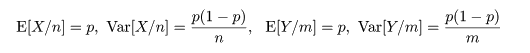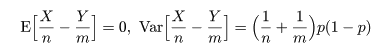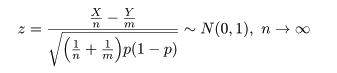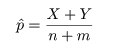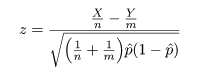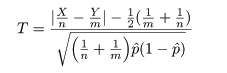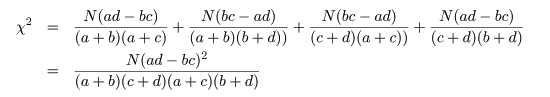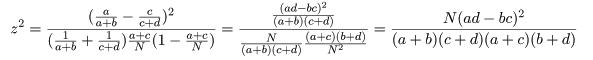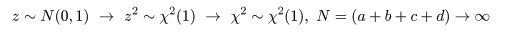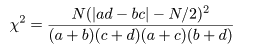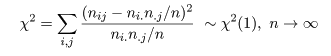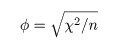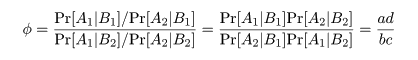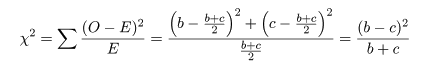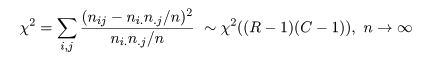統計特論2
東京大学大学院農学生命科学研究科 大森宏
この講義の目的
統計解析ソフトRを用いて,多変量解析手法の理論と解釈を学ぶ
0.前期レポート
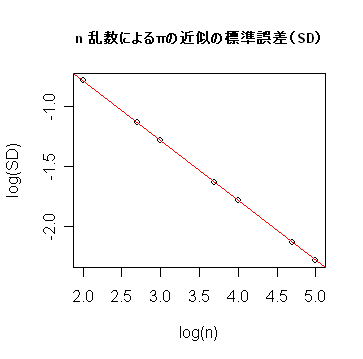
- レポート1:乱数点の個数 n を大きくしたとき,πの近似誤差の大きさの減少の程度を n のオーダー
で表せ.
-
# レポート1の R スクリプト
|
pi.f <- function(n){ | # 乱数点の個数 n のとき,πの近似の標準誤差を出力する関数
|
|
N <- 10000 | # 点セット列の長さ |
|
#n <- 1000 | # 乱数点の個数 |
|
pi <- NULL | # pi の定義 |
|
for(i in 1:N){ | # N 回の繰り返し |
|
x <- runif(n, -1, 1) | # (-1, 1) の範囲の一様乱数 n 個生成 |
|
y <- runif(n, -1, 1) | # |
|
r <- x^2 + y^2 | # 原点からの距離の2乗 |
|
pi <- c(pi, 4*length(r[r<1])/n) | # πの近似値ベクトル |
|
} | # |
|
m = mean(pi) | # 近似値の平均 |
|
s = sd(pi) | # 近似値の標準偏差 |
|
m | # 平均の表示 |
|
return(s) | # 標準偏差の表示 |
|
} | # |
|
# | # |
|
nn <- c(100,500,1000,5000,10000) | # n の値のベクトル(50000, 100000をカット) |
|
y <- NULL | # 標準誤差を格納するベクトル |
|
for(i in 1:length(nn)) | # |
|
y <- c(y, pi.f(nn[i])) | # |
|
# | # |
|
plot(nn,y, xlab="乱数の個数 n",ylab="標準誤差 SD") | # 普通にプロット |
|
plot(log10(nn),log10(y), xlab="log(n)",ylab="log(SD)") | # 両対数でのプロット |
|
z <- lm(log10(y) ~ log10(nn)) | # 直線回帰 |
|
abline(z, col="red") | # 回帰直線の表示 |
|
title(main="n 乱数によるπの近似の標準誤差(SD)", cex.main=0.8) |
|
summary(z) | # 回帰分析結果 |
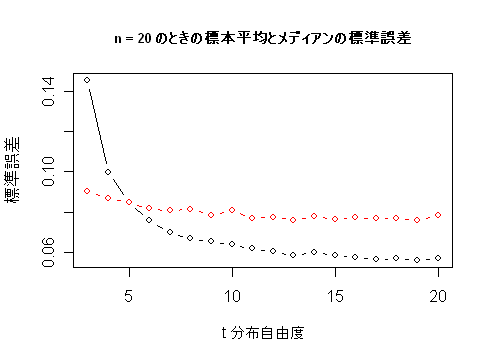
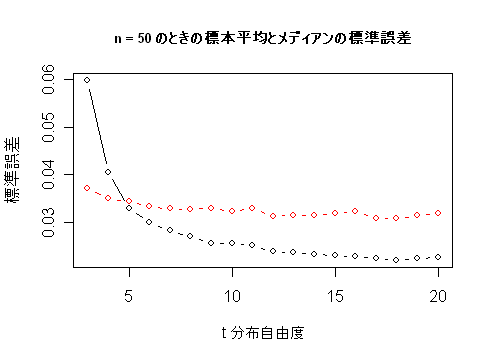
- レポート2:メディアンと標本平均の分散が同程度になる t 分布の自由度を求めよ.
-
# レポート2の R スクリプト
|
med.f <- function(n, m){ | # サンプルサイズ n,t 分布自由度 m, |
|
N <- 10000 | # シミュレーション回数 |
|
#m <- 2 | # t 分布自由度 |
|
#n <- 20 | # サンプルサイズ |
|
y1 <- NULL | # |
|
y2 <- NULL | # |
|
for(i in 1:N){ | # |
|
x <- rt(n, df=m) | # t 分布乱数 n 個 |
|
y1 <- c(y1, mean(x)) | # 標本平均列 |
|
y2 <- c(y2, median(x)) | # メディアン列 |
|
} | # |
|
m1 <- mean(y1); m2 <- mean(y2) | # 標本平均とメディアンの平均 |
|
s1 <- var(y1); s2 <- var(y2) | # 標本平均とメディアンの分散 |
|
s2/s1 | # 分散比 |
|
sqrt(s1) | # 標本平均の標準誤差 |
|
sqrt(s2) | # メディアンの標準誤差 |
|
ss <- c(s1,s2) | # 標準誤差ベクトル |
|
return(ss) | # |
|
} | # |
|
res20 <- NULL | # 標準誤差行列 |
|
for(i in 1:20) | # |
|
res20<- rbind(res20,med.f(20, i)) | # n = 20 |
|
x <- 3:20 | # |
|
plot(x, res20[3:20,1], type="b", xlab="t 分布自由度", ylab="標準誤差")
|
|
points(x,res20[3:20,2], type="b", col="red") | # |
|
title(main="n = 20 のときの標本平均とメディアンの標準誤差", cex.main=0.8)
|
|
res50 <- NULL | # |
|
for(i in 1:20) | # |
|
res50<- rbind(res50,med.f(50, i)) | # n = 50 |
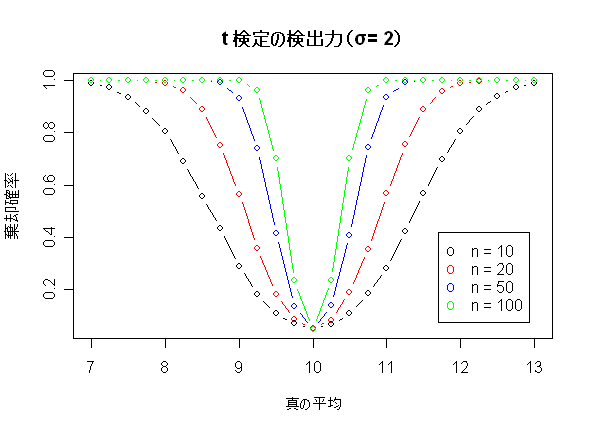
- レポート3: t 検定の検出力関数(帰無仮説の母平均 μ0 = 10 ).
-
# レポート3の R スクリプト
|
power.f <- function(n,m){ | #サンプルサイズ n,t 分布自由度 m |
|
N <- 10000 | # シミュレーション回数 |
|
#n <- 10 | # サンプルサイズ |
|
n1 <- rnorm(N*n, mean=m, sd=2) | # N(10, 4) から大きさ n の標本を N 回シミュレーション |
|
n1.mat <- matrix(data=n1, ncol=n) | # データ行列 |
|
n1.mean <- apply(n1.mat, 1, mean) | # 各サンプルの平均 |
|
n1.var <- apply(n1.mat, 1, var) | # 各サンプルの分散 |
|
n1.var3 <- n1.var/n | # 各標本平均の分散 |
|
n1.td <- (n1.mean - 10)/sqrt(n1.var3) | # 各サンプルの t 値 |
|
mean(n1.td) | # t 値の平均 |
|
sd(n1.td) | # t 値の標準偏差 |
|
mt <- ceiling(max(abs(n1.td))) | # t 値の絶対値の最大値 |
|
xq1 <- qt(0.025, df = (n-1)) | # t(9) の 2.5% 点 |
|
xq2 <- qt(0.975, df = (n-1)) | # t(9) の 97.5% 点 |
|
ns <- length( n1.td[abs(n1.td) > xq2]) | # 5% 検定で有意となった個数 |
|
return(ns/N) | # 棄却確率 |
|
} | # |
|
x <- seq(8.5,11.5,by=0.25) | # 真の平均(区間を短くした) |
|
n <- 10 | # サンプルサイズ 10 |
|
y <- NULL | # |
|
for(i in 1:length(x)) | # |
|
y <- c(y, power.f(n,x[i])) | # 棄却確率ベクトル |
|
n <- 20 | # サンプルサイズ 20 |
|
y2 <- NULL | # |
|
for(i in 1:length(x)) | # |
|
y2 <- c(y2, power.f(n,x[i])) | # |
|
n <- 50 | # サンプルサイズ 50 |
|
y3 <- NULL | # |
|
for(i in 1:length(x)) | # |
|
y3 <- c(y3, power.f(n,x[i])) | # |
|
n <- 100 | # サンプルサイズ 100 |
|
y4 <- NULL | # |
|
for(i in 1:length(x)) | # |
|
y4 <- c(y4, power.f(n,x[i])) | # |
|
plot(x,y, type="b", xlab="真の平均", ylab="棄却確率", ylim=c(0,1))
|
|
points(x,y2, type="b",col="red") | # |
|
points(x,y3, type="b",col="blue") | # |
|
points(x,y4, type="b",col="green") | # |
|
title(main="t 検定の検出力(σ= 2)") | # |
|
legend(11.7,0.42, c("n = 10","n = 20","n = 50","n = 100"),pch="o",col=c("black","red","blue","green"))
|
1.分割表の解析
対象をいくつかの質的変数でカテゴリーに分けることはよく行われる.たとえば,社会科学データでは,
人間集団を性別,年齢,職業,趣味などで分類する.ここで興味がもたれるのは,たとえば,被験者の社会的属性
(性別,年齢,学歴など)により,ある問題に対する意見や趣味嗜好が異なっているかどうか,である.これを
統計学的に書き直すと,属性ごとで意見分布が同じかどうかを検定することに帰着する.
この問題は,統計特論3で考えた,成功確率(比率)の検定からの拡張と捉えることができる.
成功確率(比率)の同等性の近似検定
成功確率 px のベルヌイ試行を n 回行ったときの成功回数を X,
成功確率 py のベルヌイ試行を m 回行ったときの成功回数を Y とする.このとき,
2つの成功確率が等しいかどうか,すなわち,
帰無仮説,H0: px = py,
対立仮説,H1: px ≠ py,
の検定を考える.帰無仮説のもとでは,px = py = p とおけるので,
px の推定量である X/n と py の推定量である Y/m の
平均と分散は,それぞれ,
となる.これより,X/n - Y/m の帰無仮説のもとで平均と分散は,
となるので,これをその平均を引いて標準偏差で割って標準化した z は,
のように漸近的に標準正規分布に従う.
ところで,帰無仮説のもとでの成功確率 p は,X と Y をこみにして,
と推定されるので,これを z に代入すれば,
となり,T = |z| を検定統計量にして,たとえば,T > 1.96 のとき帰無仮説を棄却すれば,
近似的な有意水準 5%の検定が行える.
なお,連続性の補正を入れた検定統計量は,
となる.
2×2分割表
上で述べた比率の同等性の検定は,別の表現ができる.すなわち,成功確率 px の試行 X では a 回成功し,
b 回失敗したが,別の成功確率 py 試行 Y では c 回成功,d 回失敗であったとする.このとき,
試行 X と試行 Y で成功確率が等しいという,
帰無仮説,H0: px = py,
対立仮説,H1: px ≠ py,
の検定を考える.
このようなデータは,
2 × 2 分割表データ
| | 成 功 | 失 敗 | 計 |
|---|
| 試行 X |
a | b | a + b |
|---|
| 試行 Y |
c | d | c + d |
|---|
| 計 |
a + c | b + d | N |
|---|
とまとめられる.ただし,N = a + b + c + d,である.
これを2×2分割表という.各試行の成功回数と失敗回数を記録した部分をセル,その外側の
「計」に対応する部分を周辺度数という.
周辺度数を固定したときに,帰無仮説のもとでの各セル期待度数は,
帰無仮説のもとでの期待度数
| | 成 功 | 失 敗 |
|---|
| 試行 X |
(a + b)(a + c)/N | (a + b)(b + d)/N |
|---|
| 試行 Y |
(c + d)(a + c)/N | (c + d)(b + d)/N |
|---|
となる.ここで,ピアソン(Pearson)のχ2 値,
を計算する.連続性の補正を入れると,
である.このとき,
Na - (a + b)(a + c) = (a + b + c + d)a - (a2 + ab + ac + bc) = ad - bc
という関係を利用すると,
2×2分割表の χ2 値は,
と計算される.
ところで,比率の同等性検定の z において,X = a,Y = c,n = a + b,m = c + d,
m + n = N,とおきかえると,
となり,z2 値が χ2 値と同じであることがわかる.これより,
と分布するので,自由度 1 の χ2 分布を利用して,成功確率の同等性の検定を行うことができる.
また,χ2 値に連続性の補正を行うときは,
とする.
Fisher の直接確率法
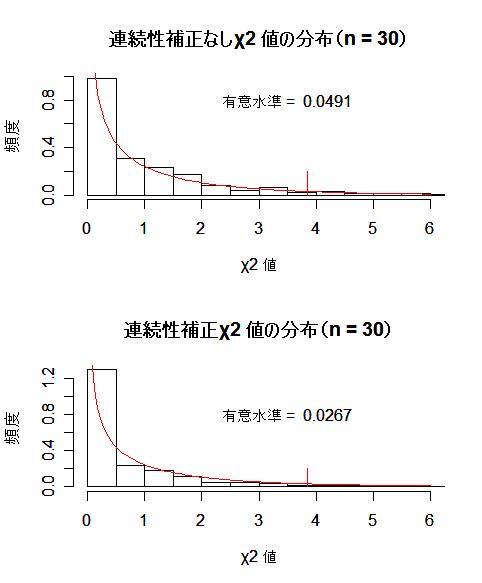
試行回数が少ないときは,各セルの期待度数が小さくなるので,近似の精度はよくない.2×2 分割表では,
一般に期待度数が 5 以下のセルがあると χ2 検定は適当でないと言われている.
このようなときは,周辺度数を固定して,データの表が得られる確率より小さな場合をすべて足し合わせて有意
確率(p 値)を計算する.
前節の囲碁と将棋の例で説明する.データを 2 × 2 分割表でまとめると以下のようになる.
将棋と囲碁 2 × 2 分割表
| | 勝 ち | 負 け |
計 | 場合の数 |
|---|
| 将 棋 |
7 | 3 |
10 | 10C7 |
|---|
| 囲 碁 |
4 | 6 |
10 | 10C4 |
|---|
| 計 |
11 | 9 |
20 | 20C11 |
|---|
上の表で,勝ち負けがまったくランダムに起こったとすると,この表ができる確率は,
p = 10C7×10C4
/20C11 = 0.15004
となる.
次に,周辺度数を固定した場合できる可能性のある表をすべて数えあげ,勝敗がランダムなときの表が
生成する確率を計算すると以下のようになる.
| パターン1 | 勝ち | 負け |
計 | 場合の数 |
| 将 棋 | 8 | 2 |
10 | 10C8 |
| 囲 碁 | 3 | 7 |
10 | 10C3 |
| 計 | 11 | 9 |
20 | 20C11 |
| 確 率 |
10C8×10C3
/20C11 = 0.03215 |
|
|
| パターン2 | 勝ち | 負け |
計 | 場合の数 |
| 将 棋 | 9 | 1 |
10 | 10C9 |
| 囲 碁 | 2 | 8 |
10 | 10C2 |
| 計 | 11 | 9 |
20 | 20C11 |
| 確 率 |
10C9×10C2
/20C11 = 0.00268 |
|
|
| パターン3 | 勝ち | 負け |
計 | 場合の数 |
| 将 棋 | 10 | 0 |
10 | 10C10 |
| 囲 碁 | 1 | 9 |
10 | 10C1 |
| 計 | 11 | 9 |
20 | 20C11 |
| 確 率 |
10C10×10C1
/20C11 = 0.00006 |
|
| |
| パターン4 | 勝ち | 負け |
計 | 場合の数 |
| 将 棋 | 6 | 4 |
10 | 10C6 |
| 囲 碁 | 5 | 5 |
10 | 10C5 |
| 計 | 11 | 9 |
20 | 20C11 |
| 確 率 |
10C6×10C5
/20C11 = 0.315075 |
|
|
| パターン5 | 勝ち | 負け |
計 | 場合の数 |
| 将 棋 | 5 | 5 |
10 | 10C5 |
| 囲 碁 | 6 | 4 |
10 | 10C6 |
| 計 | 11 | 9 |
20 | 20C11 |
| 確 率 |
10C5×10C6
/20C11 = 0.315075 |
|
|
| パターン6 | 勝ち | 負け |
計 | 場合の数 |
| 将 棋 | 4 | 6 |
10 | 10C4 |
| 囲 碁 | 7 | 3 |
10 | 10C7 |
| 計 | 11 | 9 |
20 | 20C11 |
| 確 率 |
10C4×10C7
/20C11 = 0.15004 |
|
| |
| パターン7 | 勝ち | 負け |
計 | 場合の数 |
| 将 棋 | 3 | 7 |
10 | 10C3 |
| 囲 碁 | 8 | 2 |
10 | 10C8 |
| 計 | 11 | 9 |
20 | 20C11 |
| 確 率 |
10C3×10C8
/20C11 = 0.03215 |
|
|
| パターン8 | 勝ち | 負け |
計 | 場合の数 |
| 将 棋 | 2 | 8 |
10 | 10C2 |
| 囲 碁 | 9 | 1 |
10 | 10C9 |
| 計 | 11 | 9 |
20 | 20C11 |
| 確 率 |
10C2×10C9
/20C11 = 0.00268 |
|
|
| パターン9 | 勝ち | 負け |
計 | 場合の数 |
| 将 棋 | 1 | 9 |
10 | 10C1 |
| 囲 碁 | 10 | 0 |
10 | 10C10 |
| 計 | 11 | 9 |
20 | 20C11 |
| 確 率 |
10C1×10C10
/20C11 = 0.00006 |
|
この中でデータのような表が得られる確率と同じかそれより小さな確率をすべて加え合わせたものが,
有意確率である.すなわち,パターン1,パターン2,パターン3,パターン6,パターン7,パターン8,
パターン9,の確率を加え合わせる.
特に,上側確率が,データとパターン1,パターン2,パターン3,を加えたもので,
上側確率:Pupper = 0.15004 + 0.03215 + 0.00268 + 0.00006 = 0.1849
であり,下側確率が残りのパターンの確率を加え,
下側確率:Plower = 0.15004 + 0.03215 + 0.00268 + 0.00006 = 0.1849
となる.有意確率(p 値)は,これを加え,
p 値:Pupper + Plower = 0.1849 + 0.1849 = 0.3698
となる.
ところで,上の表の確率は,白石(将棋) m = 10,黒石(囲碁)n = 10 から勝ち k = 11 を取り出したときの
将棋の勝ち数 x の分布で,これは超幾何分布である.これより,有意確率は超幾何分布から出すことができる.
クロス集計と独立性の検定
n 標本を2つの変数 A,B で分類したとき,2つの変数に関連があるかを調べたい.
変数 A を集団属性(集団1,集団2),変数 B を反応パターン(反応1,反応2)とした
とき,データは以下のようにまとめられる.これをクロス集計と呼ぶ.
2 × 2 分割表データ
| | 反応1 | 反応2 | 計 |
|---|
| 集団1 | n11 |
n12 |
n1・ |
|---|
| 集団2 | n21 |
n22 |
n2・ |
|---|
| 計 | n・1 |
n・2 |
n |
|---|
ここで,nij は,集団 i の標本の中で,反応 j を取った人数(度数)
である.また,ni・ は集団 i の標本の大きさで,
n・j は標本全体(大きさ n)の中で反応 j を取った人数
を表し,それぞれ周辺度数という.
このような表において,集団で反応パターンに違いがなければ,集団 i で反応 j を取る確率は,
集団 i である確率 ni・/n に
集団 j である確率 n・j/n をかけた
ni・n・j/
n2 となることが期待される.これより,
集団 i で反応 j を取る人数(度数)は,
ni・n・j/n
となることが期待される.これを独立性の仮定という.
いま,集団 i の標本の中で,反応 j を取る確率を pij とし,集団 i の周辺確率を pi.,
反応 j の周辺確率を p.j とすると,独立性の仮説は,
帰無仮説,H0: pij = pi.p.j,
対立仮説,H1: pij ≠ pi.p.j,
の検定になる.帰無仮説のもとで,表現は違うが前節とまったく同じ χ2 値が,
と分布するので,独立性の検定を行うことができる.連続性の補正も前節とまったく同じようにして行う.
すなわち,比率の同等性の検定と独立性の検定は,意味が違うが検定のやり方はまったく同じである.
φ(ファイ)係数
2 × 2 分割表において,変数 A と変数 B の間の関連の強さを表す指標.
四分点相関係数(four-fold point correlation coefficient)とも言う.
前節の将棋の例でみると,「将棋」
という変数と「勝ち」という変数を考える.「将棋」は将棋を行ったとき 1 を取り,「将棋」を行わなかった
とき 0 を取る.「勝ち」は勝ったとき 1 を取り,負けたとき 0 を取るものとする.
すると,全部で 20 回の対戦結果は,
| 「将棋」 |
11111111110000000000 |
|---|
| 「勝ち」 |
11111110001111000000 |
|---|
のようにまとめられる.φ 係数は,この 2 つの変数間のピアソン相関係数である.
すなわち,「将棋」と「勝ち」の相関である.
多少の計算により,ピアソン χ2 値との関係は,
であることがわかる.
# φ 係数の R スクリプト
a <- c(rep(1, 10), rep(0, 10)) # 「将棋」の値
b <- c(rep(1, 7), rep(0, 3), rep(1, 4), rep(0, 6)) #「勝ち」の値
cor(a, b) # φ 係数(a,b 間の相関係数)
n <- length(a)
shogi <- c(7, 3) # A の将棋の勝ち負け数
igo <- c(4, 6) # A の囲碁の勝ち負け数
x <- rbind(shogi, igo)
c2 <- chisq.test(x, correct=F)$statistic # ピアソン χ2 値(連続性補正なし)
sqrt(c2/n) # φ 係数
|
オッズ比(odds ratio)
変数 A,B 間の関連の強さを測る指標としてオッズ比がある.
たとえば,食中毒事件が起きたとき,
食中毒症状が出たか出なかったか(変数 A)を
出された食材を食べた人と食べなかった人(変数 B)で
分類する.このとき,ある食材に対しての分類は以下のようであったとする.
| | 発症あり(A1) | 発症なし(A2) |
|---|
| 食べた(B1) | a | b |
|---|
| 食べなかった(B2) | c | d |
|---|
食材を食べたときに発症する確率 Pr[A1| B1] の推定値は a/(a + b),
発症しない確率 Pr[A2| B1] の推定値は b/(a + b) である.
これより,その食材を食べたとき食中毒を発症する危険率(オッズ)は,
Pr[A1| B1]/P[A2| B1] = a/b
であり,同様に食べなかったときの発症オッズは,
Pr[A1| B2]/P[A2| B2] = c/d
である.この両者の比,
をオッズ比といい,ある食材を食べたことが食中毒症状発症にどれだけ危険であるかの尺度になる.
危険が同等のときは,オッズ比は 1 となる.なお,どこかのセルデータが 0 であったときは,
セルのすべての値に 0.5 を加えて補正する.
ところで,R の fisher.test() では,超幾何分布に基づいてオッズ比の最尤推定を
行っているらしいので,上の式の単純な推定値とは値が多少異なっているが,ソースの解読を
していないので詳細は不明である.
ピアソン χ2 検定は,
帰無仮説 H0:オッズ比 φ = 1
の検定と同等である.
シンプソンのパラドックス
2 元分割表に層構造があるとき,層ごとで解析しないと誤った結論を導くことがある.
たとえば,ある政策に対する賛否を 400 名に尋ね,性別,年齢層べつに集計したところ以下のようになった.
| | 賛成 | 反対 | 計 |
|---|
| 男 | 132 | 67 | 199 |
|---|
| 女 | 93 | 108 | 201 |
|---|
| 計 | 225 | 175 | 400 |
|---|
| |
| | 賛成 | 反対 | 計 |
|---|
| 35 未満 | 131 | 67 | 198 |
|---|
| 35 以上 | 94 | 108 | 202 |
|---|
| 計 | 225 | 175 | 400 |
|---|
|
これをみると,男性は約 2/3 が賛成してあり,年齢別では 35 未満の賛成も約 2/3 であった.
この結果をみると,若い男性がこの政策に賛成していると考えがちである.しかし,性別,年齢別に細かく
集計してみると,
| | 賛成 | 反対 | 計 |
|---|
| 男 35 未満 | 41 | 58 | 99 |
|---|
| 男 35 以上 | 91 | 9 | 100 |
|---|
| 計 | 132 | 67 | 199 |
|---|
| |
| | 賛成 | 反対 | 計 |
|---|
| 女 35 未満 | 90 | 9 | 99 |
|---|
| 女 35 以上 | 3 | 99 | 102 |
|---|
| 計 | 93 | 108 | 201 |
|---|
|
となり,35 歳未満の男性の反対がけっこう多く,予想とは異なる結果となった.このようになった理由は,35 歳
以上の男女で賛否がまったく異なっていて,さらに女性でも 35 歳未満と以上で賛否がまったく異なって
いたからである.このような状況を無視して,年齢層でひとくくりにしたり,性別でひとくくりしたことが
誤った推論を引き起こす原因となったと考えられる.
このように,まったく異なった性格を持つ集団をまとめてしまってデータの解釈を行うことは危険である.
したがって,2 元分割表に基づいて分析をするときは,集団の中に層構造が隠れていないかよく調べる
必要がある.
マンテル・ヘンツェル(Mantel-Haenszel)検定
分割表に層構造があるかを調べる検定
# マンテル・ヘンツェル検定の R スクリプト
Data <-
array(c(41, 91, 58, 9,
90, 3, 9, 99),
dim = c(2, 2, 2),
dimnames = list(
年齢 = c("35 未満", "35 以上"),
賛否 = c("賛成", "反対"),
性別 = c("男性", "女性")))
Data
mantelhaen.test(Data)
|
マクネマー(McNemar)検定
分割表において,非対角成分である i,j 成分と j,i 成分が等しい(i≠j)を帰無仮説とする検定.
この検定は,同一の被験者集団に時期をおいて,首相や政党などへの支持を尋ねたとき,支持が変化したかを
みたいときに用いられる.たとえば,ある政策に対する賛否を時期を開けて尋ねたところ,以下の表
になったとしよう.
| | 賛成(2 回目) | 反対(2 回目) |
|---|
| 賛成(1 回目) | a | b |
|---|
| 反対(1 回目) | c | d |
|---|
1 回目と 2 回目で意見が変わらなかった人数は a と d であり,意見が変わったのが b と c である.
帰無仮説は,
H0:1 回目と 2 回目で賛否の比率が変わらない.
である.帰無仮説のもとでは,反対 → 賛成と賛成 → 反対と変化した人数が等しく (b + c)/2 である
ことが期待される.すると,ピアソンの χ2 値は,
となるので,これが検定統計量になる.
- 大統領支持率変化のマクネマー検定
R のサンプルデータで紹介されている Agresti (1990) のデータによる.選挙権のある年齢の
アメリカ人のランダムサンプル 1,600 名の 1 か月での大統領の支持率の変化が以下の表になった.
大統領の支持率に変化があったかを調べてみよう.
| | 支持(2 回目) | 不支持(2 回目) |
|---|
| 支持(1 回目) | 794 | 150 |
|---|
| 不支持(1 回目) | 86 | 570 |
|---|
# マクネマー検定の R スクリプト
Performance <-
matrix(c(794, 86, 150, 570),
nrow = 2,
dimnames = list("1 回目調査" = c("支持", "不支持"),
"2 回目調査" = c("支持", "不支持")))
Performance
mcnemar.test(Performance) # 適切な検定
chisq.test(Performance) # 適切でない検定
|
R × C 表
大きさ n の標本を2つの変数 A,B で分類したとき,2つの変数に関連があるかを調べたい.
変数 A が R 個のカテゴリー A1, A2,…,AR,に分かれ,
変数 B が C 個のカテゴリー B1, B2,…,BC,に分かれていると
すると,標本のうち,カテゴリー Ai,Bj に落ちた個数を
nij とすると,以下のようび R × C 表にクロス集計される.
R × C 分割表データ
| | B1 | B2 |
… | BC | 計 |
|---|
| A1 | n11 |
n12 |
… |
n1C |
n1・ |
|---|
| A2 | n21 |
n22 |
… |
n2C |
n2・ |
|---|
| : | : |
: | … |
: | : |
|---|
| AR | nR1 |
nR2 |
… |
nRC |
nR・ |
|---|
| 計 | n・1 |
n・2 |
… |
n.C |
n |
|---|
すると,2 × 2 分割表のときと同様に,
集団 i の標本の中で,反応 j を取る確率を pij とし,集団 i の周辺確率を pi.,
反応 j の周辺確率を p.j とすると,独立性の仮説は,
帰無仮説,H0: pij = pi.p.j,
対立仮説,H1: pij ≠ pi.p.j,
の検定になる.帰無仮説のもとで χ2 値が,
と分布するので,独立性の検定や頻度分布の同等性の検定を行うことができる.
参考文献(古い順)
- Introduction to the Theory of Statistics, Mood, A. M., Graubill, F. A. & Boes, D. C., 1974,
McGRAW-HILL
- 工学のためのデータサイエンス入門−フリーな統計環境Rを用いたデータ解析−,間瀬茂ら,2004,
数理工学社
- 実践生物統計学−分子から生態まで−(第 1 章,第 2 章),
東京大学生物測定学研究室編(大森宏ら),
2004,朝倉書店
- The R Tips データ解析環境 R の基本技・グラフィックス活用集,船尾暢男,2005,九天社
- R で学ぶデータマインニング I −データ解析の視点から−,熊谷悦生・船尾暢男,2007,九天社
- R で学ぶデータマインニング II −シミュレーションの視点から−,熊谷悦生・船尾暢男,2007,九天社
Copyright (C) 2008, Hiroshi Omori. 最終更新日:2013年 4月13日