とおける.ただし,μ は総平均,αi は施肥効果,βj は品種効果,(αβ)ij は 施肥量と品種の交互作用,ρk はブロック効果, e1ijk は 1 次誤差、e2ijk は 2 次誤差である.ブロック効果は、 ρk 〜 N(0,σB2)を満たす変量(確率変数)で、 誤差は,e1ijk 〜 N(0,σ12)、e2ijk 〜 N(0,σ22) を満たす互いに独立な変量であるとする.
1 次誤差を用いて施肥効果やブロック効果を検定し、2 次誤差を用いて品種効果や施肥と品種の交互作用を検定する。このため乱隗法に比べ、 1 次因子(施肥量)の効果に対する精度は落ちるが、2 次因子(品種)や交互作用に対する精度は向上すると考えられる。
rice <- read.csv("Rice2019.csv") # データ読み込み
dim(rice)
attach(rice) # rice の使用宣言
y <- Grain_yield # 収量を解析形質にする
Rep <- factor(Rep)
MainMean <- tapply(y, Main_plot, mean); MainMean
SubMean <- tapply(y, Subplot, mean); SubMean
RepMean <- tapply(y, Rep, mean); RepMean
GrandMean <- mean(y); GrandMean
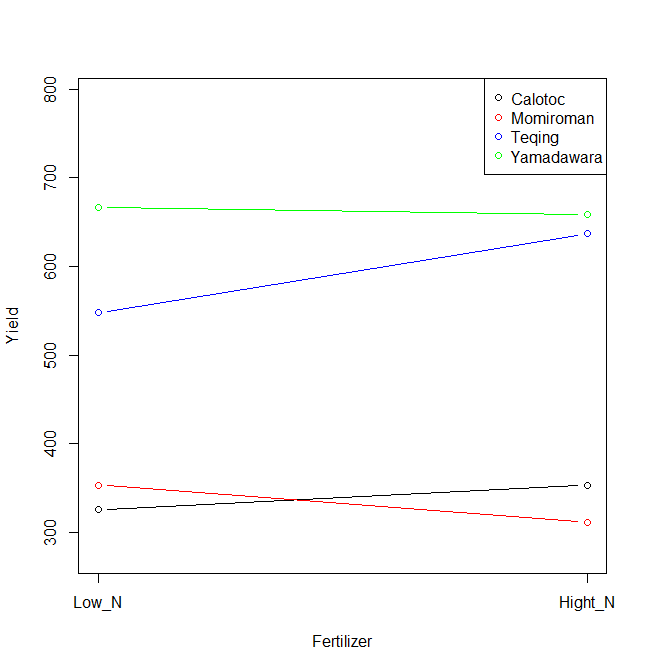
x <- tapply(y, Subplot:Main_plot, mean); x
# Calotoc:High_N Calotoc:Low_N Momiroman:High_N Momiroman:Low_N
# 353.1541 325.8600 311.4992 353.3201
# Teqing:High_N Teqing:Low_N Yamadawara:High_N Yamadawara:Low_N
# 637.1483 548.0262 658.2531 666.3392
#収量のグラフ表示
plot(1:2, x[2:1], type="b", ylim=range(y), xaxt="n", xlab="Fertilizer", ylab="Yield")
axis(1, 1:2, labels = c("Low_N", "Hight_N"))
points(1:2, x[4:3], type="b", col="red")
points(1:2, x[6:5], type="b", col="blue")
points(1:2, x[8:7], type="b", col="green")
legend("topright", legend=c("Calotoc","Momiroman","Teqing","Yamadawara"),
pch=1, col=c("black","red","blue","green"))
# 分割区法分散分析
summary(aov(y ~ Main_plot*Subplot + Error(Rep/Main_plot)))
#
# 平方和分解の詳細
a = 2; b = 4; r = 3
# 1 次因子
RepEffect <- RepMean - GrandMean
RepV <- RepEffect[Rep]
RepSS <- sum(RepV^2); RepSS # 12390:ブロック平方和
RepMS <- RepSS/(r - 1); RepMS # 6195:ブロック平均平方
MainEffect <- MainMean - GrandMean
MainV <- MainEffect[Main_plot]
MainSS <- sum(MainV^2); MainSS # 1658.804:1 次因子平方和
MainMS <- MainSS/(a - 1); MainMS # 1658.804:1 次因子平均平方
MainRepMean <- tapply(y, Main_plot:Rep, mean); MainRepMean
MM3 <- rep(MainMean, each=3)
RM2 <- rep(RepMean, 2)
GM6 <- rep(GrandMean, 6)
MainRepEffect <- MainRepMean - MM3 - RM2 + GM6; MainRepEffect
Error1V <- MainRepEffect[Main_plot:Rep]
Err1SS <- sum(Error1V^2); Err1SS # 3920.167:1 次誤差平方和
Err1MS <- Err1SS/((a -1)*(r - 1)); Err1MS # 1960.084:1次誤差平均平方
RepF <- RepMS/Err1MS; RepF # 3.16058:ブロック F 値
RepP <- 1 - pf(RepF, r-1, (a -1)*(r - 1)); RepP # 0.2403511:ブロック p 値
MainF <- MainMS/Err1MS; MainF # 0.8462927:1 次因子 F 値
MainP <- 1 - pf(MainF, a-1, (a -1)*(r - 1)); MainP # 0.4547188:1 次因子 p 値
# 2 次因子
SubEffect <- SubMean - GrandMean
SubV <- SubEffect[Subplot]
SubSS <- sum(SubV^2); SubSS # 524504.3:2 次因子平方和
SubMS <- SubSS/(b - 1); SubMS # 174834.8:2 次因子平均平方
MainSubMean <- tapply(y, Main_plot:Subplot, mean); MainSubMean
MM4 <- rep(MainMean, each=4); MM4
SM2 <- rep(SubMean, 2); SM2
GM8 <- rep(GrandMean, 8); GM8
MainSubEffect <- MainSubMean - MM4 - SM2 + GM8; MainSubEffect
MainSubV <- MainSubEffect[Main_plot:Subplot]
MainSubSS <- sum(MainSubV^2); MainSubSS # 14094.34:交互作用平方和
MainSubMS <- MainSubSS/((a - 1)*(b - 1)); MainSubMS # 4698.114:交互作用平均平方
GMV <- rep(GrandMean, length(y))
Error2V <- y - GMV - RepV - MainV - Error1V - SubV -MainSubV
Err2SS <- sum(Error2V^2); Err2SS # 35846.14:2 次誤差平方和
Err2MS <- Err2SS/(a*(b - 1)*(r - 1)); Err2MS # 2987.179:2 次誤差平均平方
SubF <- SubMS/Err2MS; SubF # 58.5284:2 次因子F値
SubP <- 1 - pf(SubF, b - 1, a*(b - 1)*(r - 1)); SubP # 1.953899e-07:2 次因子 p 値
MainSubF <- MainSubMS/Err2MS; MainSubF # 1.57276:交互作用 F 値
MainSubP <- 1 - pf(MainSubF, (a - 1)*(b - 1), a*(b - 1)*(r - 1)); MainSubP # 0.2472641:交互作用 p 値
#結果
Error: Rep
Df Sum Sq Mean Sq F value Pr(>F)
Residuals 2 12390 6195
Error: Rep:Main_plot
Df Sum Sq Mean Sq F value Pr(>F)
Main_plot 1 1659 1659 0.846 0.455
Residuals 2 3920 1960
Error: Within
Df Sum Sq Mean Sq F value Pr(>F)
Subplot 3 524504 174835 58.528 1.95e-07 ***
Main_plot:Subplot 3 14094 4698 1.573 0.247
Residuals 12 35846 2987
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1
| 要因 | 自由度 | 平方和 | 平均平方 | F 値 | p 値 | |
|---|---|---|---|---|---|---|
| ブロック | 2 | 12390 | 6195 | 3.161 | 0.240 | |
| 1 次因子(施肥量) | 1 | 1659 | 1659 | 0.846 | 0.455 | |
| 1 次誤差 | 2 | 3920 | 1960 | |||
| 2 次因子(品種) | 3 | 524504 | 174835 | 58.528 | 0 | *** |
| 施肥量×品種 | 3 | 14094 | 4698 | 1.573 | 0.247 | |
| 2 次誤差 | 12 | 35846 | 2987 |
施肥効果は全体的に無く、品種による収量の違いが大きく認められた。また、交互作用も認められなかった。
とおける。ただし,μ は総平均,αi は施肥効果,βj は品種効果,(αβ)ij は 施肥量と品種の交互作用,ρk はブロック効果, eijk は誤差である.ブロック効果は、 ρk 〜 N(0,σB2)を満たす変量(確率変数)で、 誤差は,eijk 〜 N(0,σ2) を満たす互いに独立な変量であるとする.
# 乱塊法分散分析 summary(aov(y ~ Main_plot*Subplot + Rep))
| 要因 | 自由度 | 平方和 | 平均平方 | F 値 | p 値 | |
|---|---|---|---|---|---|---|
| ブロック | 2 | 12390 | 6195 | 2.181 | 0.150 | |
| 施肥量 | 1 | 1659 | 1659 | 0.584 | 0.457 | |
| 品種 | 3 | 524504 | 174835 | 61.552 | 0 | *** |
| 施肥量×品種 | 3 | 14094 | 4698 | 1.654 | 0.222 | |
| 誤差 | 14 | 39766 | 2840 |
分割区法と乱塊法での計算上の違いは、誤差平方和の違いだけである。乱塊法における自由度 14 の 誤差平方和 39,766 が、分割区法では自由度 2 の 1 次誤差 3,920 と自由度 12 の 2 次誤差35,846に分解(3920 + 35846 = 39766) される。今回は 1 次誤差がそれほど大きくなかったので 2 次誤差はそれほど小さくならなかった。場合により、 1 次誤差が大きくなったときは 2 次誤差が小さくなるので、このときは乱塊法より分割区法の方が交互作用の検出力が 増す可能性がある。