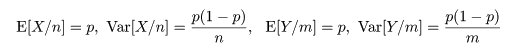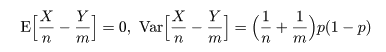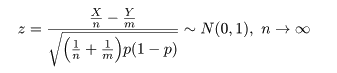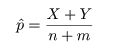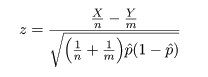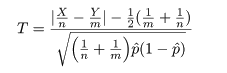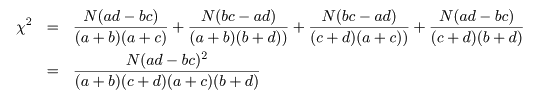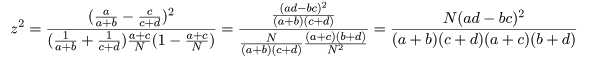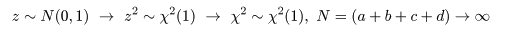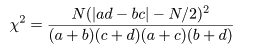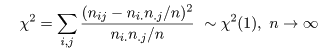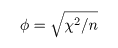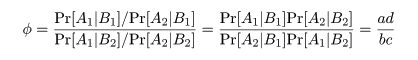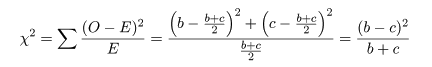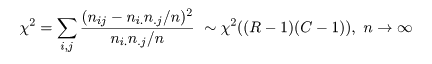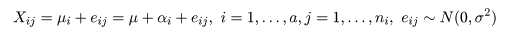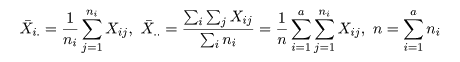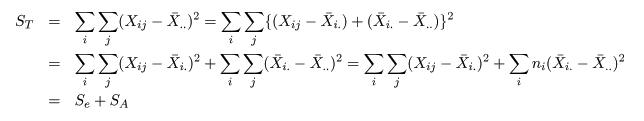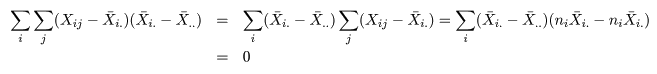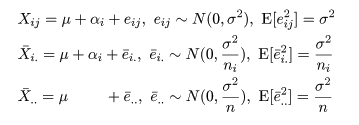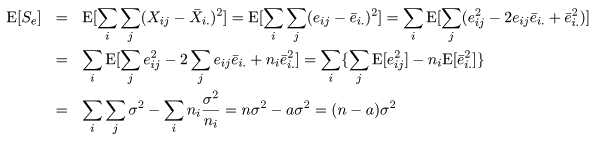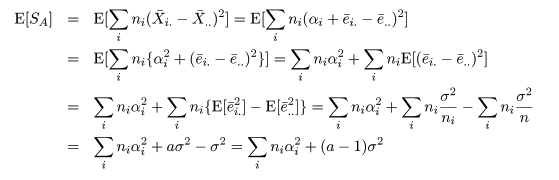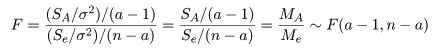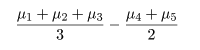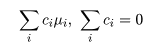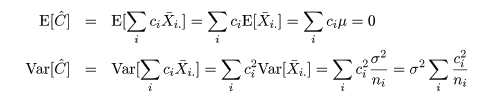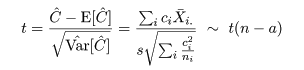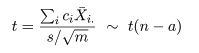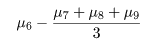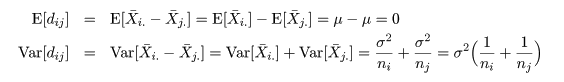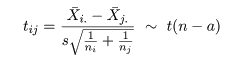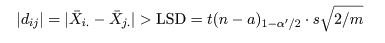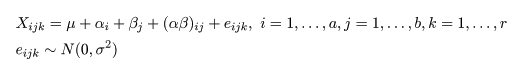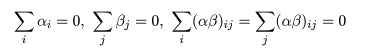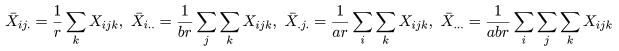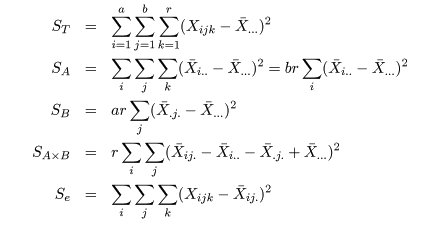東京国際大学大学院
心理データ解析(後期)
東京大学大学院農学生命科学研究科 大森宏
1.分割表の解析
対象をいくつかの質的変数でカテゴリーに分けることはよく行われる.たとえば,社会科学データでは,
人間集団を性別,年齢,職業,趣味などで分類する.ここで興味がもたれるのは,たとえば,被験者の社会的属性
(性別,年齢,学歴など)により,ある問題に対する意見や趣味嗜好が異なっているかどうか,である.これを
統計学的に書き直すと,属性ごとで意見分布が同じかどうかを検定することに帰着する.
成功確率(比率)の同等性の近似検定
成功確率 px のベルヌイ試行を n 回行ったときの成功回数を X,
成功確率 py のベルヌイ試行を m 回行ったときの成功回数を Y とする.このとき,
2つの成功確率が等しいかどうか,すなわち,
帰無仮説,H0: px = py,
対立仮説,H1: px ≠ py,
の検定を考える.帰無仮説のもとでは,px = py = p とおけるので,
px の推定量である X/n と py の推定量である Y/m の
平均と分散は,それぞれ,
となる.これより,X/n - Y/m の帰無仮説のもとで平均と分散は,
となるので,これをその平均を引いて標準偏差で割って標準化した z は,
のように漸近的に標準正規分布に従う.
ところで,帰無仮説のもとでの成功確率 p は,X と Y をこみにして,
と推定されるので,これを z に代入すれば,
となり,T = |z| を検定統計量にして,たとえば,T > 1.96 のとき帰無仮説を棄却すれば,
近似的な有意水準 5%の検定が行える.
なお,連続性の補正を入れた検定統計量は,
となる.
2×2分割表
上で述べた比率の同等性の検定は,別の表現ができる.すなわち,成功確率 px の試行 X では a 回成功し,
b 回失敗したが,別の成功確率 py の試行 Y では c 回成功,d 回失敗であったとする.このとき,
試行 X と試行 Y で成功確率が等しいという,
帰無仮説,H0: px = py,
対立仮説,H1: px ≠ py,
の検定を考える.
このようなデータは,
2 × 2 分割表データ
| | 成 功 | 失 敗 | 計 |
|---|
| 試行 X |
a | b | a + b |
|---|
| 試行 Y |
c | d | c + d |
|---|
| 計 |
a + c | b + d | N |
|---|
とまとめられる.ただし,N = a + b + c + d,である.
これを2×2分割表という.各試行の成功回数と失敗回数を記録した部分をセル,その外側の
「計」に対応する部分を周辺度数という.
周辺度数を固定したときに,帰無仮説のもとでの各セル期待度数は,
帰無仮説のもとでの期待度数
| | 成 功 | 失 敗 |
|---|
| 試行 X |
(a + b)(a + c)/N | (a + b)(b + d)/N |
|---|
| 試行 Y |
(c + d)(a + c)/N | (c + d)(b + d)/N |
|---|
となる.ここで,ピアソン(Pearson)のχ2 値,
を計算する.このとき,
Na - (a + b)(a + c) = (a + b + c + d)a - (a2 + ab + ac + bc) = ad - bc
という関係を利用すると,
2×2分割表の χ2 値は,
と計算される.
ところで,比率の同等性検定の z において,X = a,Y = c,n = a + b,m = c + d,
m + n = N,とおきかえると,
となり,z2 値が χ2 値と同じであることがわかる.これより,
と分布するので,自由度 1 の χ2 分布を利用して,成功確率の同等性の検定を行うことができる.
また,χ2 値に連続性の補正を行うときは,
とする.
Fisher の直接確率法
試行回数が少ないときは,各セルの期待度数が小さくなるので,近似の精度はよくない.2×2 分割表では,
一般に期待度数が 5 以下のセルがあると χ2 検定は適当でないと言われている.
このようなときは,周辺度数を固定して,データの表が得られる確率より小さな場合をすべて足し合わせて有意
確率(p 値)を計算する.
前節の囲碁と将棋の例で説明する.データを 2 × 2 分割表でまとめると以下のようになる.
将棋と囲碁 2 × 2 分割表
| | 勝 ち | 負 け |
計 | 場合の数 |
|---|
| 将 棋 |
7 | 3 |
10 | 10C7 |
|---|
| 囲 碁 |
4 | 6 |
10 | 10C4 |
|---|
| 計 |
11 | 9 |
20 | 20C11 |
|---|
上の表で,勝ち負けがまったくランダムに起こったとすると,この表ができる確率は,
p = 10C7×10C4
/20C11 = 0.15004
となる.
次に,周辺度数を固定した場合できる可能性のある表をすべて数えあげ,勝敗がランダムなときの表が
生成する確率を計算すると以下のようになる.
| パターン1 | 勝ち | 負け |
計 | 場合の数 |
| 将 棋 | 8 | 2 |
10 | 10C6 |
| 囲 碁 | 3 | 7 |
10 | 10C5 |
| 計 | 11 | 9 |
20 | 20C11 |
| 確 率 |
10C8×10C3
/20C11 = 0.03215 |
|
|
| パターン2 | 勝ち | 負け |
計 | 場合の数 |
| 将 棋 | 9 | 1 |
10 | 10C9 |
| 囲 碁 | 2 | 8 |
10 | 10C2 |
| 計 | 11 | 9 |
20 | 20C11 |
| 確 率 |
10C9×10C2
/20C11 = 0.00268 |
|
|
| パターン3 | 勝ち | 負け |
計 | 場合の数 |
| 将 棋 | 10 | 0 |
10 | 10C10 |
| 囲 碁 | 1 | 9 |
10 | 10C1 |
| 計 | 11 | 9 |
20 | 20C11 |
| 確 率 |
10C10×10C1
/20C11 = 0.00006 |
|
| |
| パターン4 | 勝ち | 負け |
計 | 場合の数 |
| 将 棋 | 6 | 4 |
10 | 10C6 |
| 囲 碁 | 5 | 5 |
10 | 10C5 |
| 計 | 11 | 9 |
20 | 20C11 |
| 確 率 |
10C6×10C5
/20C11 = 0.315075 |
|
|
| パターン5 | 勝ち | 負け |
計 | 場合の数 |
| 将 棋 | 5 | 5 |
10 | 10C5 |
| 囲 碁 | 6 | 4 |
10 | 10C6 |
| 計 | 11 | 9 |
20 | 20C11 |
| 確 率 |
10C5×10C6
/20C11 = 0.315075 |
|
|
| パターン6 | 勝ち | 負け |
計 | 場合の数 |
| 将 棋 | 4 | 6 |
10 | 10C4 |
| 囲 碁 | 7 | 3 |
10 | 10C7 |
| 計 | 11 | 9 |
20 | 20C11 |
| 確 率 |
10C4×10C7
/20C11 = 0.15004 |
|
| |
| パターン7 | 勝ち | 負け |
計 | 場合の数 |
| 将 棋 | 3 | 7 |
10 | 10C3 |
| 囲 碁 | 8 | 2 |
10 | 10C8 |
| 計 | 11 | 9 |
20 | 20C11 |
| 確 率 |
10C3×10C8
/20C11 = 0.03215 |
|
|
| パターン8 | 勝ち | 負け |
計 | 場合の数 |
| 将 棋 | 2 | 8 |
10 | 10C2 |
| 囲 碁 | 9 | 1 |
10 | 10C9 |
| 計 | 11 | 9 |
20 | 20C11 |
| 確 率 |
10C2×10C9
/20C11 = 0.00268 |
|
|
| パターン9 | 勝ち | 負け |
計 | 場合の数 |
| 将 棋 | 1 | 9 |
10 | 10C1 |
| 囲 碁 | 10 | 0 |
10 | 10C10 |
| 計 | 11 | 9 |
20 | 20C11 |
| 確 率 |
10C1×10C10
/20C11 = 0.00006 |
|
この中でデータのような表が得られる確率と同じかそれより小さな確率をすべて加え合わせたものが,
有意確率である.すなわち,パターン1,パターン2,パターン3,パターン6,パターン7,パターン8,
パターン9,の確率を加え合わせる.
特に,上側確率が,データとパターン1,パターン2,パターン3,を加えたもので,
上側確率:Pupper = 0.15004 + 0.03215 + 0.00268 + 0.00006 = 0.1849
であり,下側確率が残りのパターンの確率を加え,
下側確率:Plower = 0.15004 + 0.03215 + 0.00268 + 0.00006 = 0.1849
となる.有意確率(p 値)は,これを加え,
p 値:Pupper + Plower = 0.1849 + 0.1849 = 0.3698
となる.
- 勝率同等性の Fisher 直接確率法検定
# 勝率同等性 Fisher 直接法の R スクリプト
|
shogi <- c(7, 3)
| # A の将棋の勝ち負け数 |
|
igo <- c(4, 6)
| # A の囲碁の勝ち負け数 |
|
x <- rbind(shogi, igo)
| # 行連結による行列化 |
|
fisher.test(x)
| # 勝率同等性 Fisher 直接確率 |
課題:
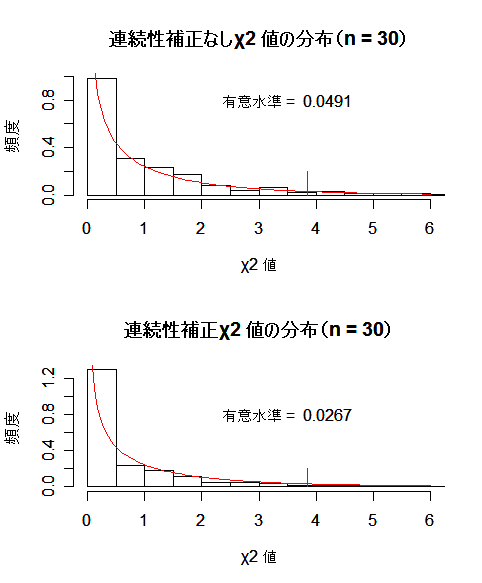
勝敗の比率はそのままで,試行回数を増やして(n = 30)同様な検定を行え.
クロス集計と独立性の検定
n 標本を2つの変数 A,B で分類したとき,2つの変数に関連があるかを調べたい.
変数 A を集団属性(集団1,集団2),変数 B を反応パターン(反応1,反応2)とした
とき,データは以下のようにまとめられる.これをクロス集計と呼ぶ.
2 × 2 分割表データ
| | 反応1 | 反応2 | 計 |
|---|
| 集団1 | n11 |
n12 |
n1・ |
|---|
| 集団2 | n21 |
n22 |
n2・ |
|---|
| 計 | n・1 |
n・2 |
n |
|---|
ここで,nij は,集団 i の標本の中で,反応 j を取った人数(度数)
である.また,ni・ は集団 i の標本の大きさで,
n・j は標本全体(大きさ n)の中で反応 j を取った人数
を表し,それぞれ周辺度数という.
このような表において,集団で反応パターンに違いがなければ,集団 i で反応 j を取る確率は,
集団 i である確率 ni・/n に
集団 j である確率 n・j/n をかけた
ni・n・j/
n2 となることが期待される.これより,
集団 i で反応 j を取る人数(度数)は,
ni・n・j/n
となることが期待される.これを独立性の仮定という.
いま,集団 i の標本の中で,反応 j を取る確率を pij とし,集団 i の周辺確率を pi.,
反応 j の周辺確率を p.j とすると,独立性の仮説は,
帰無仮説,H0: pij = pi.p.j,
対立仮説,H1: pij ≠ pi.p.j,
の検定になる.帰無仮説のもとで,表現は違うが前節とまったく同じ χ2 値が,
と分布するので,独立性の検定を行うことができる.連続性の補正も前節とまったく同じようにして行う.
すなわち,比率の同等性の検定と独立性の検定は,意味が違うが検定のやり方はまったく同じである.
φ(ファイ)係数
2 × 2 分割表において,変数 A と変数 B の間の関連の強さを表す指標.
四分点相関係数(four-fold point correlation coefficient)とも言う.
前節の将棋の例でみると,「将棋」
という変数と「勝ち」という変数を考える.「将棋」は将棋を行ったとき 1 を取り,「将棋」を行わなかった
とき 0 を取る.「勝ち」は勝ったとき 1 を取り,負けたとき 0 を取るものとする.
すると,全部で 20 回の対戦結果は,
| 「将棋」 |
11111111110000000000 |
|---|
| 「勝ち」 |
11111110001111000000 |
|---|
のようにまとめられる.φ 係数は,この 2 つの変数間のピアソン相関係数である.
すなわち,「将棋」と「勝ち」の相関である.
多少の計算により,ピアソン χ2 値との関係は,
であることがわかる.
# φ 係数の R スクリプト
a <- c(rep(1, 10), rep(0, 10)) # 「将棋」の値
b <- c(rep(1, 7), rep(0, 3), rep(1, 4), rep(0, 6)) #「勝ち」の値
cor(a, b) # φ 係数(a,b 間の相関係数)
n <- length(a)
shogi <- c(7, 3) # A の将棋の勝ち負け数
igo <- c(4, 6) # A の囲碁の勝ち負け数
x <- rbind(shogi, igo)
c2 <- chisq.test(x, correct=F)$statistic # ピアソン χ2 値(連続性補正なし)
sqrt(c2/n) # φ 係数
|
オッズ比(odds ratio)
変数 A,B 間の関連の強さを測る指標としてオッズ比がある.
たとえば,食中毒事件が起きたとき,
食中毒症状が出たか出なかったか(変数 A)を
出された食材を食べた人と食べなかった人(変数 B)で
分類する.このとき,ある食材に対しての分類は以下のようであったとする.
| | 発症あり(A1) | 発症なし(A2) |
|---|
| 食べた(B1) | a | b |
|---|
| 食べなかった(B2) | c | d |
|---|
食材を食べたときに発症する確率 Pr[A1| B1] の推定値は a/(a + b),
発症しない確率 Pr[A2| B1] の推定値は b/(a + b) である.
これより,その食材を食べたとき食中毒を発症する危険率(オッズ)は,
Pr[A1| B1]/P[A2| B1] = a/b
であり,同様に食べなかったときの発症オッズは,
Pr[A1| B2]/P[A2| B2] = c/d
である.この両者の比,
をオッズ比といい,ある食材を食べたことが食中毒症状発症にどれだけ危険であるかの尺度になる.
危険が同等のときは,オッズ比は 1 となる.なお,どこかのセルデータが 0 であったときは,
セルのすべての値に 0.5 を加えて補正する.
ところで,R の fisher.test() では,超幾何分布に基づいてオッズ比の最尤推定を
行っているらしいので,上の式の単純な推定値とは値が多少異なっているが,ソースの解読を
していないので詳細は不明である.
ピアソン χ2 検定は,
帰無仮説 H0:オッズ比 φ = 1
の検定と同等である.
シンプソンのパラドックス
2 元分割表に層構造があるとき,層ごとで解析しないと誤った結論を導くことがある.
たとえば,ある政策に対する賛否を 400 名に尋ね,性別,年齢層べつに集計したところ以下のようになった.
| | 賛成 | 反対 | 計 |
|---|
| 男 | 132 | 67 | 199 |
|---|
| 女 | 93 | 108 | 201 |
|---|
| 計 | 225 | 175 | 400 |
|---|
| |
| | 賛成 | 反対 | 計 |
|---|
| 35 未満 | 131 | 67 | 198 |
|---|
| 35 以上 | 94 | 108 | 202 |
|---|
| 計 | 225 | 175 | 400 |
|---|
|
これをみると,男性は約 2/3 が賛成してあり,年齢別では 35 未満の賛成も約 2/3 であった.
この結果をみると,若い男性がこの政策に賛成していると考えがちである.しかし,性別,年齢別に細かく
集計してみると,
| | 賛成 | 反対 | 計 |
|---|
| 男 35 未満 | 41 | 58 | 99 |
|---|
| 男 35 以上 | 91 | 9 | 100 |
|---|
| 計 | 132 | 67 | 199 |
|---|
| |
| | 賛成 | 反対 | 計 |
|---|
| 女 35 未満 | 90 | 9 | 99 |
|---|
| 女 35 以上 | 3 | 99 | 102 |
|---|
| 計 | 93 | 108 | 201 |
|---|
|
となり,35 歳未満の男性の反対がけっこう多く,予想とは異なる結果となった.このようになった理由は,35 歳
以上の男女で賛否がまったく異なっていて,さらに女性でも 35 歳未満と以上で賛否がまったく異なって
いたからである.このような状況を無視して,年齢層でひとくくりにしたり,性別でひとくくりしたことが
誤った推論を引き起こす原因となったと考えられる.
このように,まったく異なった性格を持つ集団をまとめてしまってデータの解釈を行うことは危険である.
したがって,2 元分割表に基づいて分析をするときは,集団の中に層構造が隠れていないかよく調べる
必要がある.
マンテル・ヘンツェル(Mantel-Haenszel)検定
分割表に層構造があるかを調べる検定
# マンテル・ヘンツェル検定の R スクリプト
Data <-
array(c(41, 91, 58, 9,
90, 3, 9, 99),
dim = c(2, 2, 2),
dimnames = list(
年齢 = c("35 未満", "35 以上"),
賛否 = c("賛成", "反対"),
性別 = c("男性", "女性")))
Data
mantelhaen.test(Data)
|
マクネマー(McNemar)検定
分割表において,非対角成分である i,j 成分と j,i 成分が等しい(i≠j)を帰無仮説とする検定.
この検定は,同一の被験者集団に時期をおいて,首相や政党などへの支持を尋ねたとき,支持が変化したかを
みたいときに用いられる.たとえば,ある政策に対する賛否を時期を開けて尋ねたところ,以下の表
になったとしよう.
| | 賛成(2 回目) | 反対(2 回目) |
|---|
| 賛成(1 回目) | a | b |
|---|
| 反対(1 回目) | c | d |
|---|
1 回目と 2 回目で意見が変わらなかった人数は a と d であり,意見が変わったのが b と c である.
帰無仮説は,
H0:1 回目と 2 回目で賛否の比率が変わらない.
である.帰無仮説のもとでは,反対 → 賛成と賛成 → 反対と変化した人数が等しく (b + c)/2 である
ことが期待される.すると,ピアソンの χ2 値は,
となるので,これが検定統計量になる.
- 大統領支持率変化のマクネマー検定
R のサンプルデータで紹介されている Agresti (1990) のデータによる.選挙権のある年齢の
アメリカ人のランダムサンプル 1,600 名の 1 か月での大統領の支持率の変化が以下の表になった.
大統領の支持率に変化があったかを調べてみよう.
| | 支持(2 回目) | 不支持(2 回目) |
|---|
| 支持(1 回目) | 794 | 150 |
|---|
| 不支持(1 回目) | 86 | 570 |
|---|
# マクネマー検定の R スクリプト
Performance <-
matrix(c(794, 86, 150, 570),
nrow = 2,
dimnames = list("1 回目調査" = c("支持", "不支持"),
"2 回目調査" = c("支持", "不支持")))
Performance
mcnemar.test(Performance) # 適切な検定
chisq.test(Performance) # 適切でない検定
|
R × C 表
大きさ n の標本を2つの変数 A,B で分類したとき,2つの変数に関連があるかを調べたい.
変数 A が R 個のカテゴリー A1, A2,…,AR,に分かれ,
変数 B が C 個のカテゴリー B1, B2,…,BC,に分かれていると
すると,標本のうち,カテゴリー Ai,Bj に落ちた個数を
nij とすると,以下のようび R × C 表にクロス集計される.
R × C 分割表データ
| | B1 | B2 |
… | BC | 計 |
|---|
| A1 | n11 |
n12 |
… |
n1C |
n1・ |
|---|
| A2 | n21 |
n22 |
… |
n2C |
n2・ |
|---|
| : | : |
: | … |
: | : |
|---|
| AR | nR1 |
nR2 |
… |
nRC |
nR・ |
|---|
| 計 | n・1 |
n・2 |
… |
n.C |
n |
|---|
すると,2 × 2 分割表のときと同様に,
集団 i の標本の中で,反応 j を取る確率を pij とし,集団 i の周辺確率を pi.,
反応 j の周辺確率を p.j とすると,独立性の仮説は,
帰無仮説,H0: pij = pi.p.j,
対立仮説,H1: pij ≠ pi.p.j,
の検定になる.帰無仮説のもとで χ2 値が,
と分布するので,独立性の検定や頻度分布の同等性の検定を行うことができる.
2.分散分析
分散分析は,ANOVA (Analysis of Variance) と略記されることもある.分散分析は,複数の処理を同時に
行ったときに,処理効果を推定するための最も基本的な手法である.データ全体の持つ情報は,総平方和
にまとめられているが,これを,処理の分散成分(処理平均平方)と誤差の分散成分(誤差平均平方)とに
分離して,その大きさを比較することにより,処理の効果を見積もるものである.
因子と水準
経済学では価格や成長率,工学では作業時間や故障率,農学では収量や抵抗性など,
調査研究したい特性を形質(character)という.着目した形質に影響を与えると考えられるもの,
例えば,収量では品種,温度,施肥量などを要因または因子(factor)という.
要因の影響を調べるためいくつかの品種を用いたり,
施肥量に段階を設けたりするが,それを水準(level)という.
一元配置(one-way layout)
構造モデル
t 検定では,2 つの処理平均の比較を行ったが,この節ではこれを拡張して,複数の処理平均の比較を行う
手法を考える.いま,a 水準の処理(treatment)A1,…,Aa,があり,
処理 Ai を行った ni 個の標本,
Xi1,…,Xini,が得られた
とする.処理 Ai からの標本は,平均 μi = μ + αi,分散 σ2
の正規分布に従うと仮定する.ここで,μ を総平均(grand mean),
αi を処理効果(treatment effect)もしくは,主効果(main effect)と言い,
Σiαi = 0,である.ここで,平均 0,分散 σ2 を持つ
誤差項(error term)eij を
導入し,標本の構造モデル,
として表現すると,データの持つ構造が理解しやすくなる.
平方和分解
いま,処理 Ai の標本平均を X-i.,
標本総平均を X-.. とすると,これらは,
と計算される.標本全体の持つ情報は,総平方和 ST(Total Sum of Squares)で表現される.これは,
のように誤差平方和 Se(Error Sum of Squares)と
処理平方和 SA(Treatment Sum of Squares)とに分解される.これは,積の項が
のように 0 となるからである.
平方和の期待値
個々の標本 Xij と処理 Ai の標本平均 X-i.,
標本総平均 X-.. の構造モデルがそれぞれ,
のようになるので,誤差平方和 Se と処理平方和 SA の期待値は,それぞれ,
のように計算できる.
帰無仮説のもとでの平方和の比の分布
一元配置モデルにおける帰無仮説は,すべての処理効果がない,つまり,
H0:αi = 0,i = 1,…,a,
である.前節の平方和の期待値から,帰無仮説のもとで,Se/σ2 は自由度 n - a の
χ2 分布に従い,SA/σ2 は自由度 a - 1 の χ2 分布に
従うことがわかる.これらの χ2 分布をその自由度で割った比の F 値は,
のように自由度 a - 1,n - a の F 分布に従う.
ここで,MA は,処理平方和 SA を
その自由度 a - 1 で割ったもので,処理平均平方(treatment mean square)と呼ばれ,処理平均から求めた
誤差分散 σ2 の推定値である.一方,Me は,誤差平方和 Se を
その自由度 n - a で割ったもので,誤差平均平方(error mean square)と呼ばれ,誤差分散の推定値である.
帰無仮説のもとでは MA と Me はほぼ等しいことが期待されるので,その比 F 値は
1 に近いことが期待される.よって,F 値が大きな値をとるときは帰無仮説が正しくないと考え,帰無仮説を
棄却する.F 値が大きいか小さいかの判断基準が対応する自由度の F 分布で決められる.
分散分析表と F 検定
一元配置モデルの解析結果は,以下の分散分析表(ANOVA table)にまとめられる.
| 変動因 | 自由度(df) | 平方和(S.S.) |
平均平方(M.S.) | F 値 |
|---|
| 主効果 | a - 1 | SA |
MA = SA/(a - 1) | MA/Me |
|---|
| 誤 差 | n - a | Se |
Me = Se/(n - a) | |
|---|
| 全 体 | n - 1 | ST |
| |
|---|
この表から検定統計量 F 値が求められる.そして,
自由度 a - 1,n - a の F 分布の 1 - γ 点(例えば 95 %点)F(a - 1,n - a)1 - γ
より F 値が大きい,すなわち,
F > F(a - 1,n - a)1 - γ
であるとき,帰無仮説を棄却すると,有意水準 γ (例えば 5 %)の検定が行える.これを,F 検定(F test)
という.
- 品種によるコメの収量の違い
水稲の9品種をそれぞれ,6区画の水田で栽培したときのアール当たりの玄米重量は以下のようであった.
このうち,A,B,D,それぞれ,同じ母本から育成された品種であり,C は標準(対照 control)品種である.
このデータは一元配置分散分析で解析できる.処理が品種で,9 水準からなっている.帰無仮説は,
H0:収量はどの品種も同じである
である.
データダウンロード
# 水稲品種収量分散分析の R スクリプト
|
yy <- read.csv("hinsyu.csv"); yy
| # csv データ読み込み |
|
n <- nrow(yy)
| # 繰り返し数 |
|
a <- ncol(yy)
| # 処理数 |
|
y <- NULL; x <- NULL
| # |
|
for(i in 1:a){
| # |
|
x <- c(x, rep(i, n))
| # 品種番号ベクトル |
|
y <- c(y, yy[,i])
| # 収量データベクトル |
|
}
| # |
|
x <- factor(x)
| # ラベル化 |
|
cbind(y,x)
| # ベクトルデータ表示 |
|
summary(aov(y ~ x))
| # 一元配置分散分析 |
|
anova(lm(y ~ x))
| # 一元配置分散分析(これでもよい) |
| # 分散分析の計算を以下で詳しくみる |
|
nn <- length(y)
| # 総データ数 |
|
s <- diag(var(yy)*(n-1))
| # 各品種内誤差 |
|
se <- sum(s); se
| # 誤差平方和 |
|
st <- var(y)*(nn-1)
| # 総平方和 |
|
sa <- st - se; sa
| # 処理平方和 |
|
va <- sa/(a - 1); va
| # 処理平均平方 |
|
ve <- se/(nn - a); ve
| # 誤差平均平方 |
|
fv <- va/ve; fv
| # F 値 |
|
pv <- 1 - pf(fv, df1=(a-1), df2=(nn-a)); pv
| # p 値 |
| # データの品種ごとのちらばりと,品種平均と標準誤差を視覚化する |
|
xm <- 1:9
| # |
|
ym <- mean(yy)
| # 品種ごとの平均 |
|
vm <- ve/n
| # 品種平均の分散 |
|
svm <- sqrt(vm)
| # 品種平均の標準誤差 |
|
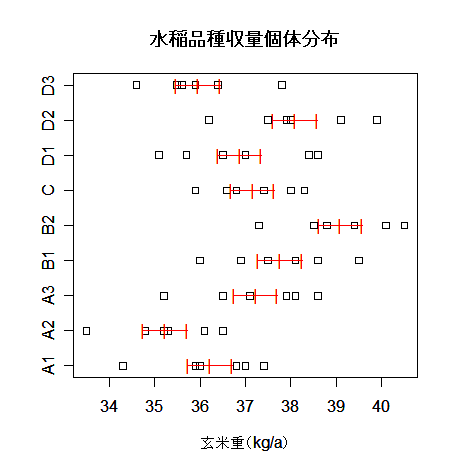
stripchart(yy, xlab="玄米重(kg/a)")
| # 品種ごとの個体分布表示 |
|
text(ym, xm,"|", col="red")
| # 品種平均 |
|
text(ym+svm, xm,"|", col="red")
| # 品種平均 + 標準誤差 |
|
text(ym-svm, xm,"|", col="red")
| # 品種平均 − 標準誤差 |
|
segments(ym-svm, xm, ym+svm, xm, col="red")
| # 横線 |
|
title(main="水稲品種収量個体分布")
| # |
水稲収量データの分散分析表は以下のようになり,品種の効果は有意確率 0.001(0.1 %)以下の *** で,
強度に有意となった.
水稲収量分散分析表
| 変動因 | 自由度(df) | 平方和(SS) |
平均平方(MS) | F 値 |
|---|
| 主効果 | 8 | 66.17 |
8.27 | 5.99 *** |
|---|
| 誤 差 | 45 | 62.09 |
1.38 | |
|---|
| 全 体 | 53 | 128.26 |
| |
|---|
また,各品種ごとの個体分布を図示すると以下のようになった.
対比(contarst)
処理平均 μi のある群と他の群との違いに特に興味がある場合がある.例えば,処理 1,2,3 の
平均と処理 4,5 の平均の間
に差があるかをみたいような場合である.一般に,
である比較を対比という.
対比 C = Σiciμi は C^
= ΣiciX-i. で推定されるが,
帰無仮説(αi = 0)のもとでは,
対比推定量の平均と分散は,
となるので,分散 σ2 をその推定量 s2 で置き換えた検定統計量 t は,
のように自由度 n - a の t 分布に従うので,対比 C = Σiciμi = 0 の
検定を行うことができる.特に,各処理水準の標本数が ni = m と一定で,対比の係数を
Σic2i = 1 と標準化すると,検定統計量は,
と簡略化される.
ところで,別の対比 Σidiμi があったときに,
Σici di = 0,となるものを直交対比という.
直交対比の組は同時に検定ができる.
事前に比較が決められるときは,後述する多重比較による有意確率の補正を行わないことが多いと思われる.
- 母本による収量の違い(対比)
前節では,すべての品種間で差がないかどうかの検定を行った.その結果,すべての品種の収量が同じという
帰無仮説は強度に有意で棄却された.ここで,母本により収量に違いがあるかを見てみよう.
いま,母本 A と B の
違いに注目しているとしよう.これは,
で表されるが,このときの対比の係数は,
c1 = (1/3, 1/3, 1/3, -1/2, -1/2, 0, 0, 0, 0)
である.この対比に直交するものとしては,例えば,標準品種 C と母本 D との間の違い,
が考えられる.この対比の係数は,
c2 = (0, 0, 0, 0, 0, 1, -1/3, -1/3, -1/3)
であり,c1 と c2 の
内積 c1'c2 = 0 なので,
c1 と c2 は直交していることがわかる.
対比の検定の結果,母本 A と B の差は強度に有意(0.1%以下)であり,母本 A からの系統
の方が収量が高いと言える.また,標準品種 C と母本 D の系統では,有意な差が認められなかった.
# 母本による収量差の対比の R スクリプト
|
c1 <- c(1/3,1/3,1/3,-1/2,-1/2, 0, 0, 0, 0)
| # 母本 A と B の平均の差の対比係数ベクトル |
|
c2 <- c(0, 0, 0, 0, 0, 1,-1/3,-1/3,-1/3)
| # 標準品種 C と母本 D の平均の差の対比係数ベクトル |
|
contrasts(x) <- cbind(c1, c2)
| # 品種ラベルに対比を定義する. |
|
contrasts(x)
| # 定義した残りの直交対比は R が勝手につくる |
|
fc <- lm(y ~ x)
| # 対比つき線形モデル |
|
summary(fc)
| # 結果表示(最初の2つの対比のみに着目) |
| # 対比の計算を詳しくみる |
|
gm <- tapply(y, x, mean); gm
| # 品種平均 |
|
cmat <- contrasts(x)[,1:2]
| # 対比係数ベクトルの必要部分 |
|
mc <- diag(t(cmat) %*% cmat)
| # 対比係数ベクトルの長さの2乗 |
|
esd <- summary(fc)$sigma
| # 誤差標準偏差の推定値 |
|
csd <- sqrt(mc)*esd/sqrt(n)
| # 対比の標準誤差 |
|
ce <- t(cmat) %*% gm
| # 対比推定値(母本平均の差) |
|
tv <- ce/csd; tv
| # 対比 t 値 |
|
2*(1 - pt(abs(tv), df=(nn-a)))
| # 対比 p 値 |
|
ce <- ce/mc; ce
| # 対比係数ベクトルの長さで補正した対比推定値 |
|
csd <- csd/mc; csd
| # 対比係数ベクトルの長さで補正した対比標準誤差 |
多重比較(multiple comparison)
分散分析(正確には実験計画)の文脈では,試験設計の段階で帰無仮説の設定が行われる.つまり,検定の内容
が事前に決定されている.このような「先付け」のときは,検定の数がそれほど多くないなら,
複数の検定を行っても有意水準についての補正を行わないのが普通だと思われる.
しかし,データが得られた後,「後付け」でどの処理間の差が有意であるか調べたい誘惑にかられることが多い.
結果として差が
大きかった処理間で t 検定を繰り返して行うと,たくさんの検定を行うので,たまたま有意になる確率が
名目上の有意水準(たとえば 5 %)を超えてしまう恐れがある.これが,多重比較である.現在では,
コンピュータにより多くの検定を簡単に行うことができるので,以前に比べて多重比較の問題を考慮しなければ
ならないと考えられる.
前節の対比でも,考えられる対比を無原則に行うときは多重比較の問題を考慮しなければならないが,この節
では対比の中でも最も単純な対比較(pairwise comparison),すなわち,
個々の処理水準間の比較のみを取り上げる.
いま,処理平均 μi と μj の比較を行う場合を考える.
2 つの処理平均の差 μi - μj は,
dij = X-i. - X-j. で推定される.
帰無仮説(αi = αj = 0)のもとで,dij の平均と分散は,
となるので,分散 σ2 をその推定量 s2 で置き換えた
検定統計量 tij は,
のように自由度 n - a の t 分布に従うので dij = 0 の検定を行うことができる.
有意水準 α'(たとえば 5 %) の検定は,
自由度 n - a の t 分布の 1 - α'/2(たとえば 97.5 %) 分位点,
t(n - a)1 - α'/2 を用いて,
が成り立つとき μi と μj の効果に違いがあると判定される.ここで,
LSD(Least squared distance)は最小有意差という量で,以前は,α' = 0.05 として,処理効果のある組み合わせ
を見つけるためよく用いられていたが,最近は,多重比較を考慮に入れた有意水準の補正を考えるのが普通
なので,単純な LSD は使用しない方が良いと思われる.
いま,a 水準の主効果があったとすると,すべての組み合わせは r = a(a - 1)/2 通りあり,「後付け」の
検定を行うときは,全体で r 回の検定を行っていると考えなければならない.
R でも
対比較では多重比較による有意確率の補正が簡単に行える.
- なにもしない
推奨されない方法である.すなわち,補正なしの t 検定を行う.昔の LSD である.
R では,|dij| の p 値が出力
される.
- ボンフェローニ(Bonferroni)補正
いま,有意水準 α' のそれぞれ独立な検定を r 回行ったとすると,1 回の検定で正しい判断を行う確率が
1 - α' なので,r 回の検定で正しい判断を行う確率は,(1 - α')r となる.よって,正しい判断
を行わない(第 1 種の過誤の)確率は,
1 - (1 - α')r ≒ 1 - (1 - rα') = rα',ただし,α' ≒ 0
となる.これが,r 回の検定全体での有意水準となる.よって,検定全体での有意水準を α にするには,
1 回の検定の有意水準を α' = α/r にすればよい.これがボンフェローニ補正である.しかし,
多重比較における検定は独立な検定ではないので,この補正は厳しすぎ(保守的)て,
有意な組み合わせが見つからない恐れがある.
R の多重比較では,補正なしの p 値を r 倍した p 値を出力する.ただし,これが 1 を超えた場合は 1 とする.
- ホルム(Holm)補正
ボンフェローニ補正を改良したものである.すべての比較組み合わせ(対比)の t 値を計算し,
それを大きさの順に並べる.一番大きな t 値 t(1) の有意確率を α/r,次の大きさ
の t(2) の有意確率を α/(r - 1),というように有意確率を調整する.
R ではホルム補正がデフォルトで,
p 値を大きさの順に並べ最も小さな p 値を r 倍し,次に大きな p 値を r - 1 倍して出力するようである.
# コメ収量多重比較の R スクリプト
|
pth <- pairwise.t.test(y, x); pth
| # 対比較ホルム補正 |
|
ptb <- pairwise.t.test(y, x, p.adj = "bonf"); ptb
| # 対比較ボンフェローニ補正 |
|
ptn <- pairwise.t.test(y, x, p.adj = "none"); ptn
| # 対比較補正なし |
|
showpt.f <- function(x, p){
| # p 値が p 以下の比較を表示する関数 |
|
pl <- which(x < p, arr.ind=TRUE)
| # 行列 x の要素が p 以下の場所 |
|
cbind(pl[,2], x[pl])
| # 場所と p 値の表示 |
|
}
| # |
|
showpt.f(pth$p.value, 0.05)
| # 対比較ホルム補正で 5 %有意となった比較 |
|
showpt.f(ptb$p.value, 0.05)
| # 対比較ボンフェローニ補正で 5 %有意となった比較 |
|
showpt.f(ptn$p.value, 0.05)
| # 対比較補正なしで 5 %有意となった比較 |
| # 多重比較の計算を詳しくみる(品種1と5の比較) |
|
c15 <- c(1,0,0,0,-1,0,0,0,0)
| # 対比ベクトル |
|
mc15 <- c15 %*% c15
| # 大きさ |
|
c15sd <- sqrt(mc15)*esd/sqrt(n)
| # 対比較の標準誤差 |
|
c15e <- t(c15) %*% gm
| # 対比較推定値 |
|
tv15 <- c15e/c15sd; tv15
| # 対比較 t 値 |
|
pv15 <- 2*(1 - pt(abs(tv15), df=(nn-a)));pv15
| # 対比較 p 値 |
|
k <- a*(a-1)/2
| # 比較の総数 |
|
pv15*k
| # 対比較 p 値ボンフェローニ補正 |
- チューキー(Tukey)の HSD(honestly significant difference)
今までは,t 検定の有意確率を補正することにより,多重比較の問題に対処していたが,
スチィーデント化された範囲の分布
(Studentized range distribution)という多重比較専用の分布
を用いて検定する.2 つの処理 i,j 間の比較
を行うときに用いる検定統計量は,先ほどの tij である.
# コメ収量 Tukey HSD の R スクリプト
|
hsd <- TukeyHSD(aov(y ~ x)); hsd
| # チューキー HSD のすべての組み合わせの結果表示 |
|
ph <- hsd$x[,4]
| # 各比較の p 値ベクトル |
|
sc <- (1:length(ph))[ph<0.05]
| # p 値が 0.05 以下の比較 |
|
hsd$x[sc,]
| # 5 %有意な比較 |
- 多重比較法による結果
コメ9品種収量の多重比較を行った結果 5 %有意となった組み合わせは以下の表にまとめられる.有意
確率の補正とチューキー HSD は似た結果を与えたが,補正なしの LSD では倍以上の組み合わせが有意
とされた.
| 多重比較法 | 共通の組み合わせ |
補正なしと HSD | 補正なし |
|---|
| ホルム補正 |
1-5 2-4
2-5 2-8
5-9 |
| |
|---|
| ボンフェローニ補正 |
|---|
| 補正なし |
5-7 | 1-4 1-8 2-3 2-6 2-7 3-5 4-9 5-6 8-9 |
|---|
| チューキー HSD | |
|---|
- 多重比較法の比較
多重比較の方法はここで取り上げた以外の手法も知られているが,R で手軽に使える手法を解説した.
ここで紹介した手法の有意水準をシミュレーションで比較してみる.標準正規乱数 50 を 1 から 5 まで
のグループに 10 個ずつ分ける.このデータを処理数 a = 5,処理内標本 n = 10 の一元配置データ
とみなす.このデータは帰無仮説が真のときで,処理平均に差がないはずである.
分散分析 F 検定の p 値とホルム補正,ボンフェローニ補正,補正なし,チューキー HSD の
多重比較の p 値の最小値
を出す.p 値の最小値が 0.05 以下であれば,5 %有意な組み合わせが少なくとも 1 つは存在
したことになる.これを,N = 10000 回繰り返して有意な組み合わせが見つかった回数を調べれば
有意水準がわかる.
その結果は以下の表のようになった.また,分散分析の F 検定で有意になったときと
そうでないときで多重比較で有意な組み合わせが見つかったかどうかも分類した.これをみると,
補正なしの多重比較は有意水準 25 %以上で,
明らかにゴーストを拾ってしまうことがわかり,これを使ってはいけないことが
示された.
一方,ホルム補正とボンフェローニ補正は,このシミュレーションでは違いがまったくなかった.
これは,p 値の最小値の補正はどちらも α/r であるからである.
有意水準が 4 %ぐらいであり,問題がないと言える.チューキー HSD の有意水準は約 5 %
で一番よいと言える.
また,分散分析 F 検定との関連をみると,多重比較の有意な組み合わせの有無は F 検定と
大きく関連があると言えるが,まったく一致しているわけではなかった.分散分析 F 検定と多重比較は
違う検定と考えた方がよいと思われる.すなわち,分散分析 F 検定が有意なときだけ多重比較を行うと
有意水準が低下するので,より保守的な検定になってしまうからである.
多重比較法の有意水準と F 検定の有意性との関係
| | F 検定 |
ホルム補正 |
ボンフェローニ補正 | 補正なし | チューキー HSD |
|---|
| 有意水準 |
0.0497 | 0.0377 |
0.0377 | 0.2807 | 0.0503 |
|---|
有意となった組み合わせ
があった回数 | 有意なとき(497) |
337 | 337 |
497 | 393 |
|---|
| 有意でないとき |
40 | 40 |
2310 | 110 |
|---|
# 多重比較法の有意水準 の R スクリプト
|
N <- 1000
| # シミュレーション回数(時間節約のため減らした) |
|
a <- 5; n <- 10
| # 処理水準数 a,処理内標本数 n |
|
x <- NULL
| # |
|
for(i in 1:a) x <- c(x, rep(i, n))
| # グループラベル |
|
x <- factor(x)
| # ラベル化 |
|
pv <- NULL
| # p 値行列 |
|
for(i in 1:N){
| # |
|
y <- rnorm(n*a)
| # 標準正規乱数 n*a 個 |
|
pth <- pairwise.t.test(y, x)
| # 対比較ホルム補正 |
|
ptb <- pairwise.t.test(y, x, p.adj = "bonf")
| # 対比較ボンフェローニ補正 |
|
ptn <- pairwise.t.test(y, x, p.adj = "none")
| # 対比較補正なし |
|
av <- aov(y ~ x)
| # 分散分析 |
|
hsd <- TukeyHSD(av)
| # チューキー HSD |
|
p0 <- summary(av)[[1]][1,5]
| # 分散分析 p 値 |
|
p1 <- min(pth$p.value, na.rm=TRUE)
| # 対比較ホルム補正の p 値の最小値 |
|
p2 <- min(ptb$p.value, na.rm=TRUE)
| # 対比較ボンフェローニ補正の p 値の最小値 |
|
p3 <- min(ptn$p.value, na.rm=TRUE)
| # 対比較補正なしの p 値の最小値 |
|
p4 <- min(hsd$x[,4])
| # チューキー HSD の p 値の最小値 |
|
pv <- rbind(pv, c(p0, p1,p2,p3,p4))
| # p 値行列に格納 |
|
}
| # |
|
fs <- (1:N)[pv[,1]<0.05]
| # 分散分析で 5 %有意となった回の番号 |
|
hs <- (1:N)[pv[,2]<0.05]
| # 対比較ホルム補正で 5 %有意な組み合わせがあった回の番号 |
|
bs <- (1:N)[pv[,3]<0.05]
| # 対比較ボンフェローニ補正で 5 %有意な組み合わせがあった回の番号 |
|
ns <- (1:N)[pv[,4]<0.05]
| # 対比較補正なしで 5 %有意な組み合わせがあった回の番号 |
|
ts <- (1:N)[pv[,5]<0.05]
| # チューキー HSD で 5 %有意な組み合わせがあった回の番号 |
|
num <- c(length(fs), length(hs), length(bs), length(ns), length(ts))
|
|
num/N
| # 有意水準 |
|
table(hs %in% fs)
| # 対比較ホルム補正の番号と分散分析有意の番号とのマッチング |
|
table(bs %in% fs)
| # 対比較ボンフェローニ補正の番号と分散分析有意の番号とのマッチング |
|
table(ns %in% fs)
| # 対比較補正なしの番号と分散分析有意の番号とのマッチング |
|
table(ts %in% fs)
| # チューキー HSD の番号と分散分析有意の番号とのマッチング |
二元配置(two-way layout)
構造モデル
2 つの因子 A,B に対し,その水準の数をそれぞれ a,b とする.同じ因子と水準の繰り返し
(repetition)を r とする.A 因子の第 i 水準で B 因子の第 j 水準の第 k 番目の標本データ
Xijk は,
とおける.μ は総平均,αi は因子 A の主効果,βj は因子 B の主効果,
(αβ)ij は因子 A と B の交互作用(interaction)で,
の制約を満たしている.eijk はモデルで説明できない誤差項である.
各種平方和
因子 A,B の第 i,j 水準の平均,因子 A の第 i 水準の平均,因子 B の第 j 水準の平均および
標本総平均をそれぞれ,
とおく.すると,総平方和 ST,因子 A の平方和 SA,
因子 B の平方和 SB,
交互作用平方和 SA×B,誤差平方和 Se はそれぞれ,
と計算される.1 元配置分散分析のときと同様に,
ST = SA + SB + SA×B + Se
という平方和の分解ができる.
分散分析表と F 検定
二元配置モデルの解析結果は,以下の分散分析表(ANOVA table)にまとめられる.
| 変動因 | 自由度(df) | 平方和(S.S.) |
平均平方(M.S.) | F 値 |
|---|
| 主効果 A | a - 1 | SA |
MA = SA/(a - 1) |
MA/Me |
|---|
| 主効果 B | b - 1 | SB |
MB = SB/(b - 1) |
MB/Me |
|---|
| 交互作用 | (a - 1)(b - 1) | SA×B |
MA×B = SA×B/(a - 1)(b - 1) |
MA×B/Me |
|---|
| 誤 差 | ab(r - 1) | Se |
Me = Se/(n - a) | |
|---|
| 全 体 | n - 1 | ST |
| |
|---|
に続く.
実験計画法(追加)
# コメ収量データ の R スクリプト
|
rice <- read.csv("ricecul.csv")
| # コメデータ読み込み |
|
rice[rice$year==2000,]
| # 2000年度データの表示 |
|
yield0 <- rice$gy[rice$year==2000]
| # 2000年度収量 |
|
dens0 <- factor(rice$density[rice$year==2000])
| # 2000年度密度水準のラベル化 |
|
fert0 <- factor(rice$fert[rice$year==2000])
| # 2000年度肥料水準のラベル化 |
|
blk0 <- factor(rice$rep[rice$year==2000])
| # 2000年度ブロックのラベル化 |
|
cbind(yield0, dens0, fert0, blk0)
| # データと変数の表示 |
|
ry.aov <- aov(yield0 ~ blk0 + dens0 + fert0 + dens0:fert0)
| # 2要因乱塊法分散分析 |
|
summary(ry.aov) | # 分散分析表表示 |
|
x <- tapply(yield0, dens0:fert0, mean); x
| # 栽植密度と施肥量組み合わせの収量平均 |
|
plot(1:3, x[1:3], type="b", lwd=2, xaxt="n", xlab="施肥量", ylab="収量", ylim=c(300, 600), pch=0, col="blue")
|
|
axis(1, 1:3, labels=c("施肥無","施肥少","施肥多"))
| # グラフ表示 |
|
points(1:3, x[4:6], type="b", lwd=2, pch=2, col="red")
| # |
|
legend(locator(1), legend=c("疎植","密植"), pch=c(0,2), col=c("blue","red"))
|
|
title(main="栽植密度と施肥量の交互作用(2000年)")
| # |
課題:収量の他の年度の分散分析を行え.
# コメ収量年次効果の R スクリプト
|
yield <- rice$gy
| # コメ収量データ |
|
dens <- factor(rice$density)
| # 密度水準のラベル化 |
|
fert <- factor(rice$fert)
| # 施肥量水準のラベル化 |
|
year <- factor(rice$year)
| # 年次のラベル化 |
|
cbind(yield, dens, fert, year)
| # データと変数の表示 |
|
rya.aov <- aov(yield ~ dens + fert + year + dens:fert + fert:year + dens:year + dens:fert:year)
|
|
summary(rya.aov)
| # 3元配置分散分析表 |
|
x <- tapply(rice$gy, fert:year, mean)
| # 年次と施肥量組み合わせの収量平均 |
|
plot(1:4, x[1:4], type="b", lwd=2, xaxt="n", xlab="年次", ylab="収量", ylim=c(300,600), pch=0, lty=1,col="red")
|
|
axis(1, 1:4, labels=levels(year))
| # グラフ表示 |
|
points(1:4, x[5:8], type="b", lwd=2, pch=2,lty=1, col="blue")
| # |
|
points(1:4, x[9:12], type="b", lwd=2, pch=3,lty=1, col="green")
| # |
|
legend(locator(1), legend=c("施肥無","施肥少","施肥多"), pch=c(0,2,3), col=c("red","blue","green"))
|
|
title(main="年次と施肥量の交互作用")
| # |
課題:他の形質の分散分析を行え.
参考文献
- 心理・教育のための統計法(第 2 版),山内光哉,1998,サイエンス社
- 工学のためのデータサイエンス入門−フリーな統計環境Rを用いたデータ解析−,間瀬茂ら,2004,
数理工学社
- 実践生物統計学−分子から生態まで−(第 1 章,第 2 章),
東京大学生物測定学研究室編(大森宏ら),
2004,朝倉書店
- R で学ぶデータマインニング I −データ解析の視点から−,熊谷悦生・船尾暢男,2007,九天社
- R で学ぶデータマインニング II −シミュレーションの視点から−,熊谷悦生・船尾暢男,2007,九天社
- 生物統計学入門,上村賢治・高野泰・大森宏,2008,オーム社
Copyright (C) 2008, Hiroshi Omori. 最終更新:2008年10月 4日