
講義プリントサイト:http://lbm.ab.a.u-tokyo.ac.jp/~omori/kokusai/kokusai06_index.htm
携帯解答サイト: http://lbm.ab.a.u-tokyo.ac.jp/~omori/k/
QRコード
前期の統計学の応用(a)では,正規分布理論に基づいて,1変量データに対する統計解析を説明した. 統計学の応用(b)では,多変量データやカテゴリーデータなどの質的データを取り扱う.まずは, 前期の復習を行い.その後2変量データの重要な解析法である回帰分析を行う.
数量データ:x1,
x2,…,xn
→サンプルサイズ(標本の大きさ):n
データの中心の位置を表す
→(標本)平均:x- = (1/n)Σi
xi = (x 1 +
x2 + …
+ xn ) / n
データのちらばりの程度を表す
→標本分散:s 2 = (1/n−1)Σi
(x i − x-)2
= {(x1 − x-)2
+(x2 − x-)2
+ … +
(xn − x-)2 }
/(n−1)
→標本標準偏差(SD:Standard Deviation):s(標本分散の平方根)
平均 μ,分散 σ2,の正規分布
から大きさ n の標本 x i 〜
N( μ,σ2 ) を抽出.
→標本平均の分散:Var[x-] = σ2/n
→標本平均の標準偏差(標準誤差 SE:Standard Error):sd[x-] = σ/√n
→標本平均の分布: x- 〜 N( μ,σ2/n )
→標準化 z = √n (x- − μ )/σ 〜 N(0,1):標準正規分布
→分散 σ2 未知
→標本分散 s 2 で推定
→ t 値: t = √n (x- − μ )/s 〜 t(n−1):自由度 n−1 の t 分布
→自由度 n − 1 の t 分布の 97.5%分位点 t0
→Pr[ − t0 < √n (x-
− μ )/ s < t0 ] = 0.95
→Pr[ x- − t0 s
/ √n < μ < x- +
t0 s / √n ] = 0.95
→母集団平均 μ の 95% 信頼区間
例題のデータは,リハビリ方式 A を3ヶ月行ったときの,身体能力の増加ポイントであるとする.
リハビリを行わなかったときの身体能力の増加は平均的にみて無いことが知られている.
リハビリ方式 A が意味のあるものであるかどうか統計的に検定する.
リハビリの効果が無いと仮定すると,身体能力の増加ポイントの平均は0であると期待される.よって,
| 仮説の棄却 | 仮説の採択 | |
|---|---|---|
| 仮説が真のとき | 第1種の過誤 | 正解 |
| 仮説が偽のとき | 正解 | 第2種の過誤 |
有意水準:帰無仮説(H0)が真のとき,仮説が棄却される確率.つまり第1種の過誤
の確率である.
仮説検定の手順.帰無仮説のもとでは,
→標本平均の分布:x- 〜 N( 0,σ2/n )
→標準化 z = √n x- /σ 〜 N(0,1)(標準正規分布)
→分散 σ2 未知
→標本分散 s 2 で推定
→ t 値: t = √n x- /s 〜 t(n−1)(自由度 n−1 の t 分布)
→自由度 n − 1 の t 分布の 97.5%分位点 t0
→絶対値 |t| 値:√n |x-| /s > t0
→帰無仮説を棄却し,リハビリに効果が認められたと判断
→絶対値 |t| 値:√n |x-| /s < t0
→帰無仮説を採択し,リハビリに効果が認められないと判断
例題1のデータは,リハビリ方式 A を3ヶ月行ったときの,身体能力の増加ポイントであるとする.
例題2のデータは,リハビリ方式 B を3ヶ月行ったときの,身体能力の増加ポイントであるとする.
リハビリを行わなかったときの身体能力の増加は平均的にみて無いことが知られている.
リハビリ方式 A と B の平均的な効果に違いがあるかどうかを統計的に検定する.
リハビリ方式 A の平均的な効果を μA,リハビリ方式 B の平均的な効果を μB
とする.
仮説検定の手順.
| データ | 標本数 | 標本平均 | 標本分散 |
| 標本 A | nA | x-A | sA2 |
| 標本 B | nB | x-B | sB2 |
| 1. A,B 共通の標本分散: | 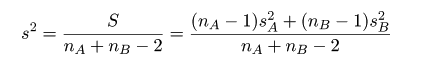 |
| 3. 平均の差の標本標準偏差(標準誤差): | 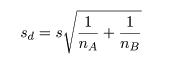 |
| 4. 検定統計量 t 値: | 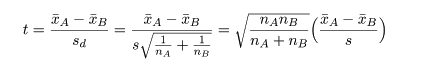 |
| データ | 標本数 | 標本平均 | 標本分散 |
| 標本 A | nA = 8 | x-A = 3 | sA2 = 16.57 |
| 標本 B | nB = 6 | x-B = 4.5 | sB2 = 17.8 |
|
| = ( 7×16.57 + 5×17.8 )/12 = ( 116 + 89 )/12 = 17.08 |
標本(サンプル)に対し,2つの変数 x,y が測定されているとする. たとえば,x が身長(m)であり,y が体重(kg)である. 大きさ n の標本(サンプル)に対し,2つの変数の組のデータが,
共分散は測定単位により大きさが変わるので,これをおのおのの変数の分散, Var(x),Var(y),
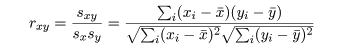
データに最もよくあてはまる直線回帰式を得るには,データ点 (xi ,yi ), と回帰による推定点, (xi ,y^i ), y^i = a + b xi , の間の距離の2乗和 S が最小になるような回帰係数 a ,b を求める.つまり,
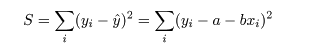
これは,S を a ,b で偏微分して 0 とおくことによって得られる.つまり,
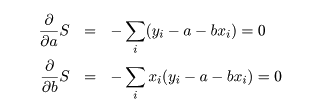
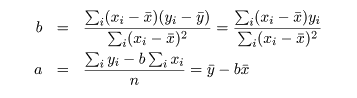
| 入試得点(x) | 680 | 500 | 600 | 420 | 480 | 630 | 550 | 590 | 610 | 500 | 640 | 570 | 610 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 初年度成績(y) | 332 | 265 | 309 | 253 | 276 | 326 | 299 | 310 | 324 | 327 | 334 | 301 | 336 |
問題1:初年度成績(y)の偏差平方和(小数点第2位)
問題2:入試得点(x)と初年度成績の偏差積和平方和(小数点第2位)
問題3:回帰係数(b)(小数点第2位)
推定された直線回帰式がどの程度現実のデータに適合しているかを調べるために, 回帰式が従う統計モデルを考える.標本の格データ点, (xi ,yi ), が,
回帰で説明がつかない残差平方和 Se は,
一般に,Var(yi ) = σ2 であるとき,その定数 倍の分散は,
回帰式により, 従属変数 y のデータ yi は,
データが直線回帰式でよく説明できるのは,回帰平方和が大きく,残差平方和 が小さい場合である.総平方和のうち回帰平方和で説明される割合を決定係数,もしくは 重相関係数の2乗といい,
| 変動因 | 平方和 | 自由度 | 平均平方 | F 値 |
|---|---|---|---|---|
| 回帰 | SR | 1 | SR | F = SR/se2 |
| 残差 | Se | n−2 | se2 = Se/n−2 | |
| 全体 | ST | n−1 |
従属変数 y が説明変数 x の回帰関係にないという 帰無仮説,
回帰係数 b の推定値 b^ の分散は,
回帰係数の標準誤差 s b を用いて, 回帰係数 b の信頼区間がつくれる.すなわち, 自由度 n−2 の t 分布の 97.5%点を t0 とすると, 回帰係数 b の 95%信頼区間の幅 d は,d = t0 s b となるので, 95%信頼区間は,
問題4:残差平方和(小数点第2位)
問題5:残差分散(小数点第2位)
問題6:重相関係数の2乗(小数点第2位)
問題7:F 値(小数点第2位)
問題8:回帰係数(b)の標準誤差(小数点第3位)
問題9:回帰係数(b)の95%信頼区間の幅 d(小数点第2位)
は自由度 m,n の F 分布に従い,F 〜 F(m, n) と表記する. m を分子の自由度,n を分母の自由度という.
ところで,回帰係数の推定値 b^ をその
標準誤差 sb で割った t 値は,
回帰関係がないという帰無仮説 H0,
| 入試得点(x) | 590 | 550 | 520 | 560 | 540 | 440 | 680 | 520 | 610 | 490 | 620 | 580 | 600 | 590 | 570 | 640 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 初年度成績(y) | 325 | 333 | 313 | 299 | 351 | 321 | 388 | 338 | 367 | 320 | 296 | 311 | 297 | 332 | 368 | 376 |
| 入試得点(x) | 540 | 530 | 660 | 540 | 570 | 710 | 450 | 650 | 580 | 590 | 490 | 600 | 570 | 580 | 520 | 610 |
| 初年度成績(y) | 348 | 346 | 389 | 359 | 343 | 361 | 273 | 264 | 354 | 356 | 324 | 363 | 323 | 323 | 338 | 338 |
| 入試得点(x) | 620 | 530 | 670 | 550 | 530 | 570 | 570 | 600 | 550 | 720 | 570 | 530 | 720 | 580 | 610 | 470 |
| 初年度成績(y) | 339 | 322 | 378 | 337 | 315 | 391 | 283 | 333 | 338 | 348 | 282 | 298 | 372 | 341 | 284 | 391 |
| 入試得点(x) | 初年度成績(y) | (x − x-)(y − y-) | |
|---|---|---|---|
| 平均 | 576.67 | 335.19 | |
| 偏差平方和 | 190066.7 | 47921.3 | 28170.0 |
問題1: x と y の相関係数(r)(小数点第3位)
問題2: x に対する y の回帰係数(b)(小数点第3位)
問題2で求めた回帰係数を用いて回帰推定値( y^ )を算出し,
回帰残差( y − y^ )を求めた.すると,残差平方和は,
Se = 43746.2,となった.
これより以下の分散分析表を完成させよ(×の欄には値が入らない).
| 変 動 因 | 平 方 和 | 自由度 | 平 均 平 方 | F 値 |
|---|---|---|---|---|
| 回 帰 | ||||
| 残 差 | 43746.2 | × | ||
| 全 体 | × | × |


| サイコロの目 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 回数 | 8 | 11 | 12 | 8 | 11 | 10 |
| サイコロの目 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 観測度数 | 8 | 11 | 12 | 8 | 11 | 10 |
| 期待度数 | 10 | 10 | 10 | 10 | 10 | 10 |
| 自由度 | 90% | 95% | 99% |
|---|---|---|---|
| 1 | 2.71 | 3.84 | 6.64 |
| 2 | 4.61 | 5.99 | 9.21 |
| 3 | 6.25 | 7.81 | 11.34 |
| 4 | 7.78 | 9.49 | 13.28 |
| 5 | 9.24 | 11.07 | 15.09 |
| 反応1 | 反応2 | 計 | |
|---|---|---|---|
| 集団1 | n11 | n12 | n1・ |
| 集団2 | n21 | n22 | n2・ |
| 計 | n・1 | n・2 | n |
| 反応1 | 反応2 | 集団周辺 | |
|---|---|---|---|
| 集団1 | n1・ n・1/n | n1・ n・2/n | n1・ |
| 集団2 | n2・ n・1/n | n2・ n・2/n | n2・ |
| 反応周辺 | n・1 | n・2 | n |
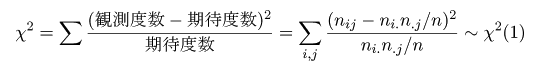
| 好き | 嫌い | 計 | |
|---|---|---|---|
| 男 | 60 | 60 | 120 |
| 女 | 40 | 90 | 130 |
| 計 | 100 | 150 | 250 |
| 男・好き | 男・嫌い | 女・好き | 女・嫌い | 計(χ2 値) | |
|---|---|---|---|---|---|
| 観測度数(O) | 60 | 60 | 40 | 90 | 250 |
| 期待度数(E) | 250 | ||||
| (O − E)2/E |
問題1:男性が好きと回答する期待度数(E)
問題2:男性が嫌いと回答する期待度数(E)
問題3:女性が嫌いと回答する期待度数(E)
問題4:男・好きのセルでの (O − E)2/E の値(小数第2位)
問題5:χ2 値(小数第1位)
| 好き | 嫌い | 計 | |
|---|---|---|---|
| 男 | 6 | 6 | 12 |
| 女 | 4 | 9 | 13 |
| 計 | 10 | 15 | 25 |
| 男・好き | 男・嫌い | 女・好き | 女・嫌い | 計(χ2 値) | |
|---|---|---|---|---|---|
| 観測度数(O) | 6 | 6 | 4 | 9 | 25 |
| 期待度数(E) | 25 | ||||
| (O − E)2/E |
問題6:χ2 値(小数第2位)
| 10代 | 20代 | 30代 | 40代 | 計 | |
|---|---|---|---|---|---|
| カップヌードル | 41 | 50 | 57 | 56 | 204 |
| シーフードヌードル | 59 | 50 | 43 | 44 | 196 |
| 計 | 100 | 100 | 100 | 100 | 400 |
問題7:好みの違いの表の自由度
問題8:好みの違いのχ2 値(小数第2位)
問題9:好みの違いのχ2 値(小数第2位)