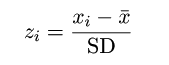2008.5.08
携帯解答サイト: http://lbm.ab.a.u-tokyo.ac.jp/~omori/k/
- 問1の先週の回答結果
-
| 選択肢 |
1:絶対金持ち | 2:多分金持ち |
3:多分貧乏 | 4:絶対貧乏 | 計 |
|---|
| 回答者数 |
1 | 16 |
12 | 1 | 30 |
-
-
多分金持ちと多分貧乏に分かれた.投稿例をみると,平均より低いので多分貧乏だろうと考えた学生と,貧富の差
や直感を考慮して多分金持ちと考えた学生に分かれた.
貯蓄分布をみると単調減少型になっていて,貯蓄の中央値(メディアン)が1024万円なので,1000万円
以上の貯蓄をもつ家庭はどちらかというと「金持ち」に分類される.
-
- 問2の先週の回答結果
-
| 選択肢 |
1:金持ち | 2:普通 |
3:貧乏 | 計 |
|---|
| 回答者数 |
9 | 19 |
2 | 30 |
-
-
普通と答えた学生が多かった.投稿例をみても,平均=普通,と考える学生が多かった.直感から
1700万円も貯める家庭は金持ちと考える学生もいた.
貯蓄分布をより詳細にみると,平均貯蓄額を下回る家庭が約2/3(67.6%)であった.このため,
平均貯蓄額以上の貯蓄を持つ家庭は,「普通」ではなく「金持ち」に分類した方がよいと思われる.
-
- 先週の投稿例
-
- 平均より下回っているから(多分貧乏)
- このデータの平均でみると貧乏だが実際は違ってくると思う.
- 1000万も貯蓄があるなら金持ちと言えるかも知れないが,平均はあくまで全体の真ん中の数値であるので
統計的にみると,おそらく貧乏だろう.
- 貧富の差が激しいとみたのと,個人的感覚で多分金持ち.
- おそらく1200万円以下の家庭の方が多いから,多分金持ち.
- 平均は普通だから.
- 今の世の中,貯蓄を1700万近くも貯めるのは難しいので,貯められる家庭は金持ちだと思う.
-
- 平均値,標本分散の計算
-
第1問:メディアン
| 内訳 |
解答者数 | 間違い |
正解 | のべ解答数 |
|---|
| 人数 |
11 | 18 |
9 | 27 |
-
-
第2問:平均
| 内訳 |
解答者数 | 間違い |
正解 | のべ解答数 |
|---|
| 人数 |
17 | 7 |
16 | 23 |
-
-
第3問:標本分散
| 内訳 |
解答者数 | 間違い |
正解 | のべ解答数 |
|---|
| 人数 |
12 | 20 |
5 | 25 |
-
-
第4問:標本標準偏差
| 内訳 |
解答者数 | 間違い |
正解 | のべ解答数 |
|---|
| 人数 |
7 | 2 |
6 | 8 |
-
-
平均の計算はできるようだが,分散や標準偏差はあまりできていない.
- 平均値,標本分散の計算(再挑戦)
以下のデータの代表値を小数第1位まで(小数第2位まで求めて四捨五入する)求めよ.
計算には電卓等を用いてよい.解答は数値解答テストで送信(半角数字)
すること.
5,-1,1.5,2,0.5,-2
第1問:メディアン(中央値)
第2問:平均値
第3問:標本分散
第4問:標準偏差(SD)
計算用紙
| データ |
5 | -1 |
1.5 | 2 |
0.5 | -2 |
| 偏差 | | | | |
| |
| 偏差平方 | | | | |
| |
4-4.形状の情報
- 単調減少(増加)型,単峰型,2峰型:ヒストグラムでわかる.
- 歪度(わいど)Skewness:歪度正→右に長く伸びる.歪度負→左に長く伸びる
- 尖度(せんど)Kurtosis:尖度 = 3 →正規分布と似た尖り.
尖度> 3 →正規分布より尖る.尖度< 3 →正規分布よりなだらか.
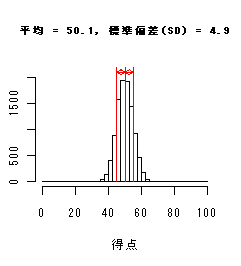
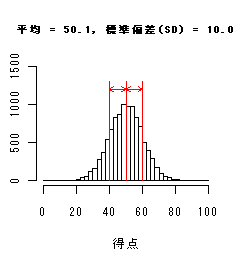
データ分布(ヒストグラム)による標準偏差(SD)の違い
以下のヒストグラムは,平均値は同じだが標準偏差が異なっている.
標準偏差(SD)が小さいときは分布が平均のまわりに集中し,大きいときは分布が広がり,
データのちらばりが大きくなっている.
単峰(つり鐘型)
 |
単峰(つり鐘型)
 |
単峰型
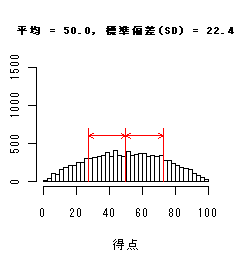 |
単調減少型
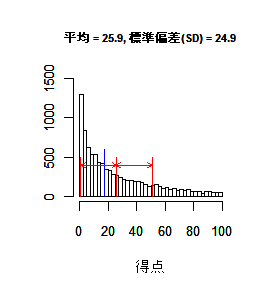
メディアン(中央値)= 17.7,歪度=1.1 |
U字型
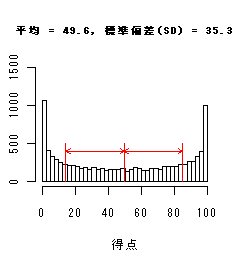
|
2峰型
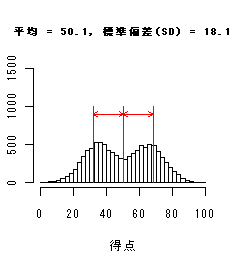
|
単峰型(左に裾が伸びる)

歪度=-0.43 |
単峰型(右に裾が伸びる)
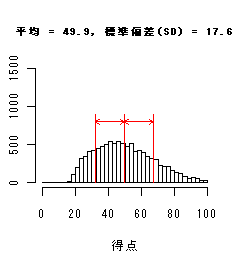
歪度=0.45
|
単峰型(右に裾が伸びる)
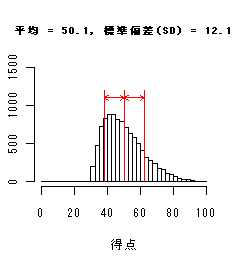
歪度=0.80 |
4-5.データ操作
- 中心化:中心化データ=データ−平均値=
xi−x-
データの偏差を取ること.中心化データの平均は 0.
- 標準化:標準化データ=(データ−平均値)/標準偏差=中心化データ/標準偏差
標準化データ(zi)の平均は 0,標準偏差は 1,(分散も1).
データを標準化すると比較がしやすくなる.
(->偏差値:平均50,標準偏差10に得点を標準化したもの)
-
例題
- 先週取り上げたデータ
9,4,6,5,-4,2,-1, 3
の平均は 3,標準偏差は 4.1 であった.これより,
データの最小値 -4 と最大値 9 の標準化した値を求めよ.
解答
最小値 -4 に対しては,(-4 - 3)/4.1 = -7/4.1 = -1.7
最大値 9 に対しては,(9 - 3)/4.1 = 6/4.1 = 2.195 = 2.2
-
問題
-
あるクラスの英語得点と国語得点の代表値が以下の表のようであった.
以下の問の解答を携帯で送信せよ.
| | 平 均 | 標準偏差 |
| 英 語 | 58.6点 | 11.6点 |
| 国 語 | 54.2点 | 16.0点 |
A君の得点は英語,国語とも65点であった.
- 問1:英語の標準化値(小数第2位)を,数値解答テスト第5問で送信
- 問2:国語の標準化値(小数第2位)を,数値解答テスト第6問で送信
- 問3:英語と国語,どちらの方が成績が良かった
と言えるか.選択肢解答テスト第3問で送信
-
| 1.国語の方がよい |
2.英語の方がよい |
3.国語と英語は同じ |
-
- 上の解答の理由を掲示板に投稿せよ.
5. 正規分布
平均 μ(ミュー),分散 σ2(シグマ 2 乗)の 2 つの
パラメータ(母数)で形が決まる.
釣りがね型の分布
標準偏差 σ が小さいほど中心に集中した分布になる.
確率変数 x がこの正規分布に従うとき,x 〜
N( μ,σ2 ),と書く.
正規分布の密度関数は,以下の通り.
5-1.正規分布のあてはめ
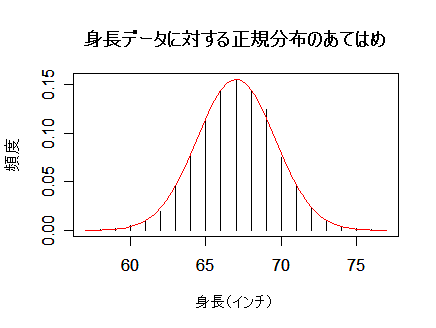
身長や体重などの身体データや得点データなどは正規分布に従うことが多い.たとえば,英国成人男子身長(インチ)
のデータに正規分布をあてはめてみる.
英国男子身長データ(インチ)
| 身長 |
57 | 58 |
59 | 60 |
61 | 62 |
63 | 64 |
65 | 66 |
| 人数 |
2 |
4 |
14 |
41 |
83 |
169 |
394 |
669 |
990 |
1223 |
| 67 |
68 | 69 |
70 | 71 |
72 | 73 |
74 | 75 |
76 | 77 |
| 1329 |
1230 |
1063 |
646 |
392 |
202 |
79 |
32 |
16 |
5 |
2 |
まず,データから統計量を求める.データ総数は 8585 名である.
平均:x- = (57*2+58*4+59*14+…+77*2)/8585 = 67.02,
分散:s2 = {(57−67.02)2*2+(58−67.02)2*4
+ …+(77−67.02)2*2}/8585 = 6.62.
これより,平均 μ = 67.02,分散 σ2 = 6.62,
の正規分布にあてはめ,赤線でグラフ表示したところ,データ分布によく一致していた.
Copyright (C) 2008, Hiroshi Omori. 最終更新:2008年 5月 8日