集合知による景観イメージの再構成
1.集合知とは
多くの人の予想や意見を総合すると,よい予想や結果が得られることがある。これを,
集合知(collective inteligence)と呼んでいる。
たとえば,英国の家畜見本市で雄牛の体重を当てるコンテストが開かれた。787名がコンテストに参加したが,その平均値は,実際の雄牛の体重1198ポンドに対し,1197ポンドという驚くほど正解に極めて近い値であった(1)。
このような集合知は以前から知られていた。たとえば,株式市場や競馬のオッズなどがこれにあたる。一番人気の馬が勝つ場合が多いことも集合知の正しさを示している。しかし,株式市場でのバブル崩壊の例などからわかるように,集合知がいつもうまくいくわけではない。
情報通信技術(ICT)の進展により,いわゆるビッグデータに象徴されるように,非常に多くの人の意見を収集して集約することが比較的容易に行われるようになってきたので,
最近注目されている概念である。
2.地域景観特性の集合知としての SLoT マップ
ある地域の景観特性を明らかにすることは,地域観光の振興や地元の住民が地域に対する愛着や満足を増進させるために重要である。地域の景観特性は,その地域との関わり方(居住者,通勤・通学者,旅行者など)や属性(男女,年齢,職業など)などにより異なると考えられる。このとき,潜在変数としての地域景観特性はその対象者との環境心理学的相互作用により顕在化されるのではないかと考えられる。
いま,ある地域において,ある属性を持った多くの観測者が「気に入った」景観を撮影し,撮影理由やそのとき感じたことなどのコメント文を記載したとすると,この2つの情報には,その地域景観のある意味魅力的な特性を反映していると考えられる。このような情報を集約して,地域景観特性の集合知を求めるのが SLoT マップ(2)である。
SLoT(Snapshot - Location - Text)とは,スナップショット(写真)とそれを撮った位置(緯度・経度),その時感じたことや印象などのコメントのテキスト文の3つの情報を1つのセットにしたデータセットのことであり,SLoTマップとは,ある地域における多くのSLoTデータを統合して作成される地域景観特性の集合知である。
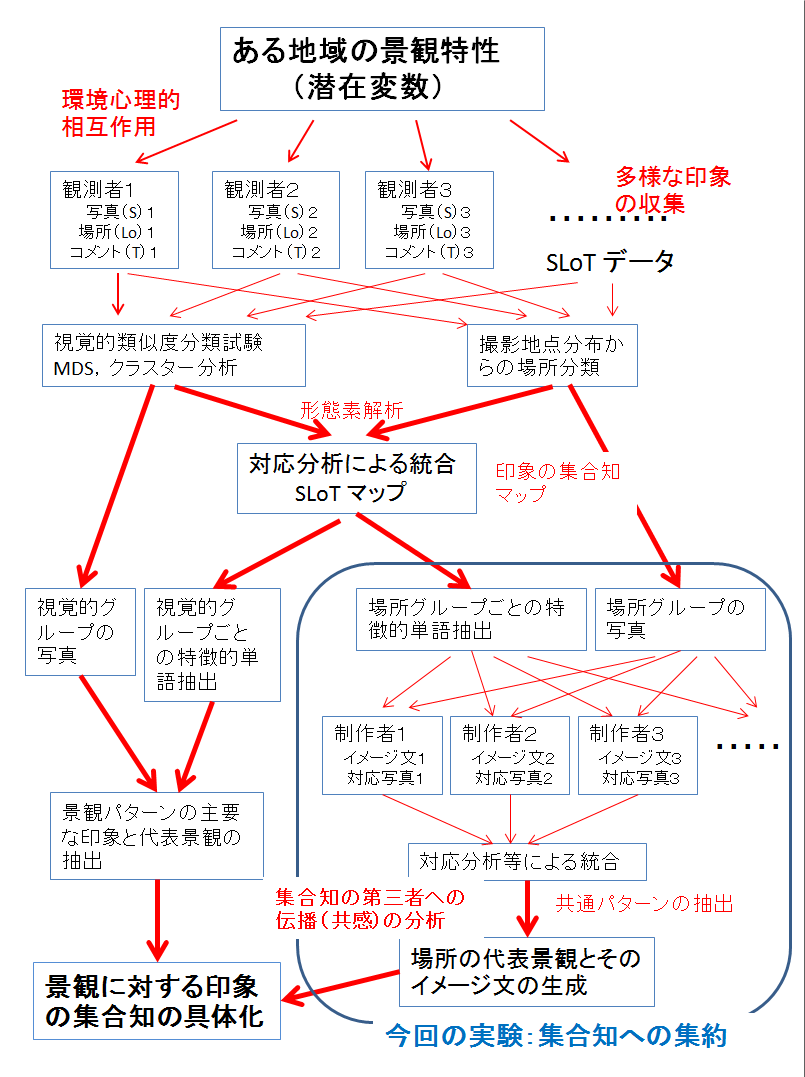
これは,まずある地域で多様なSLoTデータを収集する。次に,スナップショットの見た目の類似性(多くの人の類似写真のグルーピング試験を集約した集合知)により分類した視覚的グループと撮影地点分布から得られる場所グループを求める。そして,RMeCab(3)などのテキストマイニングソフトを用いて,コメント文を名詞,形容詞,動詞などの形態素(単語)に分解し,どの形態素がどのコメント文に使用されたかを示す形態素×コメント行列を作成する。この行列に視覚的グループと場所グループのコメントカテゴリーを加え合わせた拡大行列を対応分析にかけるとSLoTマップが得られる。
SLoTマップでの場所グループと視覚的グループの配置から,コメント文で見た場所グループ間や視覚的グループとの印象の関係が示される。また,視覚的グループは調査対象地域全体が持つ景観パターンの集合知を表現したもので,そこで特徴的に使用された単語から景観パターンが与える主要な印象を示している。また,場所グループは調査対象地域のある特定の地区の印象の集合知を与え,そこで特徴的に使用された単語群からその地区の印象の集合知が示される。
ここで,場所グループごとの印象の集合知をよりわかりやすく具体的な表現で示すために,そこで特徴的に使用された単語を用いたイメージ文を作成し,そのイメージ文に合った写真をその場所で撮られた写真を選ぶことでその特定の場所が与えるイメージが表現できると考えられる。
以下に,SLoTマップ法による景観イメージを再構成してまとめる手順の概念図を示す。
3.イメージ文の集合知による生成
今回の実験は上の図の青で囲った部分を行う。SLoTデータは多様なので,このままではその地域の景観特性を分析することは難しく,分析者により多様な解釈が生まれてしまう。そこで,SLoT マップで平均的な印象を集約したことにより,各場所のイメージは固まっていて分析者による解釈の違いは少なくなって来ている考えられる。しかし,このイメージをイメージ文として具体化すると,分析者により多少のずれが生じると考えられる。
そこで,イメージ文を多くの人に作成してもらい,そこから共通のイメージを抽出してイメージ文を作成すれば,より具体的で説得力のあるイメージ文が作成されると考えられる。また,個々人の作成したイメージ文の違いを分析することにより,その個人とはまったく関係のない地域の観察者が感じた環境心理的な印象が,どの程度第三者に伝播(共感)されるかを分析することができると考えられる。
イメージ文の生成と代表的景観の抽出法を東京本郷地区における景観調査の例で説明する。以下の図の上側は,この地区の本郷通り周辺で何人かの観測者により撮影された写真を並べている。左側の表は,この場所で特徴的に使用された単語を並べたものである。
ある制作者は,単語表から黄色で色づけされた単語を組み合わせて『「東大」「正門」前の「イチョウ」「並木」は「散歩」すると「気持ちよい」。』というイメージ文を作成し,このイメージ文に合った写真を上側の写真群から選んだ。また,青色で色づけされた単語を組み合わせて,もう一つのイメージ文を作成し,それに合った写真を選んだ。このようにして,観測者の場所に対する印象の集合知を再構成することにより,その場所の景観イメージを具体的に表現することができた。
4.川越市の景観特性の集合知
川越市は,埼玉県の南西部に位置する人口約33万人の都市で,平安時代から交通の要衝,入間地区の政治の中心として発展してきた.江戸時代には江戸の北の守りとともに舟運を利用した物質の集積地として重要視された.明治になると,穀物・織物・たんすなどの特産物で埼玉県一の商業都市として繁栄した.明治26年(1893)に大火に見舞われたが,耐火性を重視した土蔵造りの店舗を建設して,現在も残る蔵造りの景観を形成した.
現在は,都心から30kmのベッドタウンでありながら,近郊農業,流通業,商工業,観光業などでこの地域の中心都市ととして発展している.首都圏に位置する「歴史と文化のまち」として脚光を浴び,年間およそ600万人の観光客が訪れている.このため,歴史のある町並みの保全とともに既存の景観との調和に配慮したしたまちづくりが進められている.(4,5).
川越市にある東京国際大学の学生が,川越にどのようなイメージを抱いているかを調査
した。2010年度と2011年度において、統計学の講義の夏休みの宿題で川越市内の気に入った景観を2、3点撮影し、撮影地点と撮影理由を記載して写メールで送付してもらった.その結果、男子学生63名、女子学生58名、外国人・不明7名から242件のデータが収集できた。
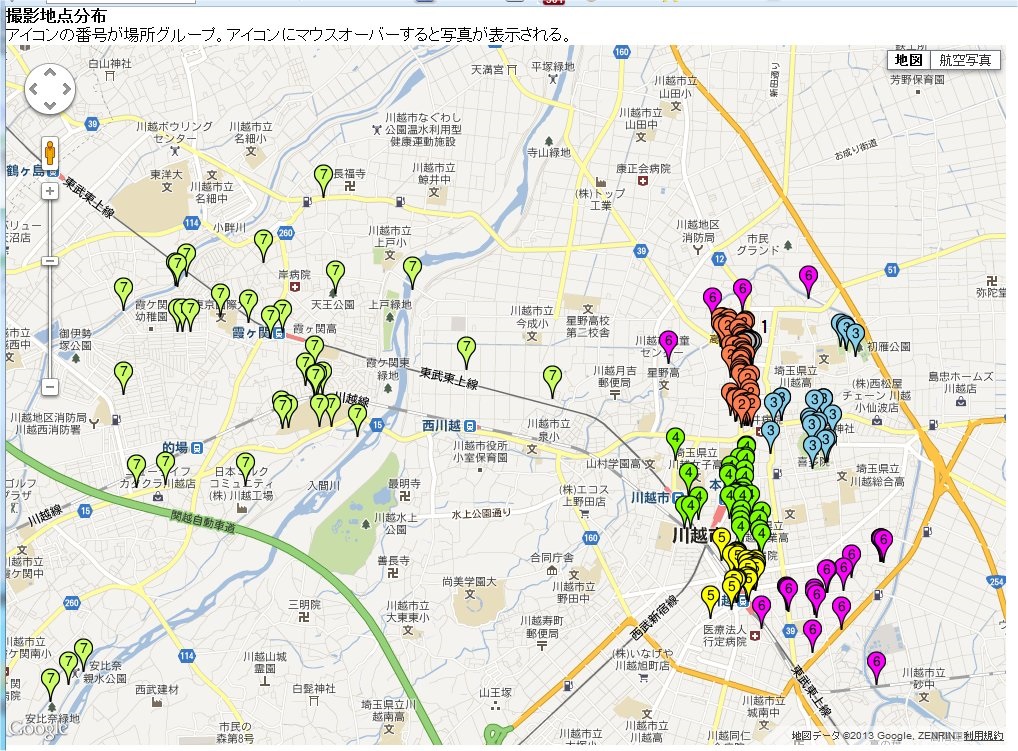
撮影地点の分布から,川越市を以下の7つのエリアに分けた.このエリアがどのようなイメージを与えたかが写真のコメント文を解析することにより分かる.
- 時の鐘(P1):41件
- 中心市街(P2):52件
- 周縁部(P3):22件
- 繁華街(P4):34件
- 川越駅周辺(P5):31件
- 郊外(P6):25件
- 霞ヶ関(P7):37件
収集データ
川越収集景観写真一覧
写真コメント一覧
撮影地点分布と場所グループ
参考資料
1) The Wisdom of Crowds. Surowiecki, J., Doubledy Broadway, 2004. (「みんなの意見」は案外正しい.小高尚子訳,角川書店,2006)
2) SLoT マップ:スナップショット・位置・テキストによる印象の集合知と街歩きマップ.大森宏・羽生和紀・山下雅子,日本建築学会計画系論文集,第78巻,第638号,159-166, 2013.
3) Rによるテキストマイニング入門,石田基広.森北出版,2008.
4) 川越市のプロフィール(川越市HP内)
http://www.city.kawagoe.saitama.jp/www/contents/1208909612154/index.html
5) 川越市の歴史(川越市HP内)
http://www.city.kawagoe.saitama.jp/www/contents/1099270027289/index.html
Copyright (C) 2009, Hiroshi Omori. 最終更新日:2013年 6月5日