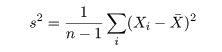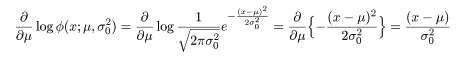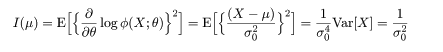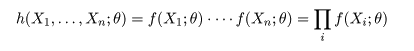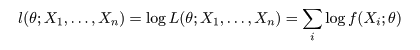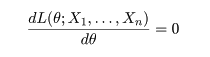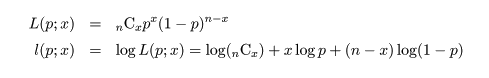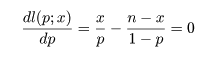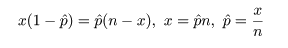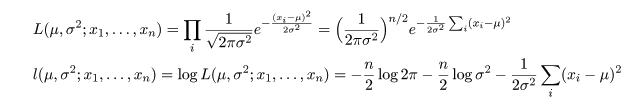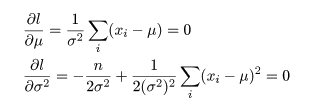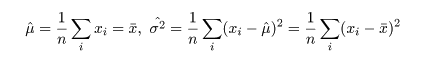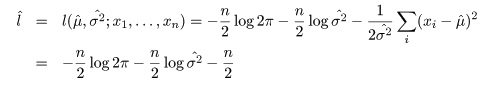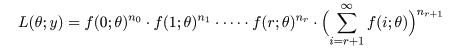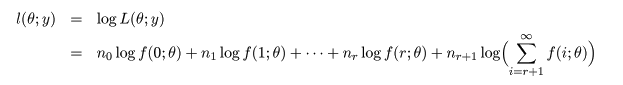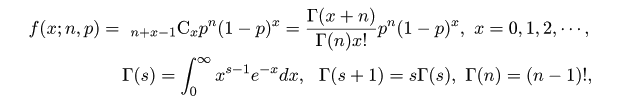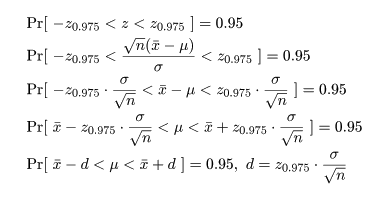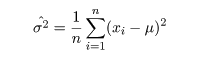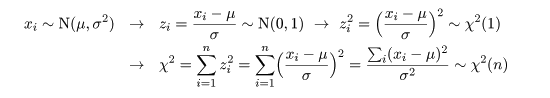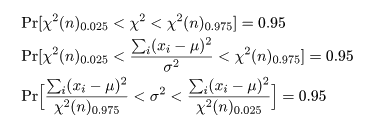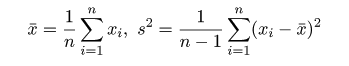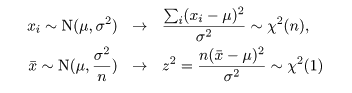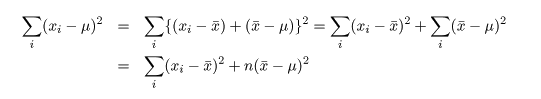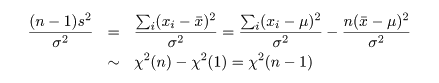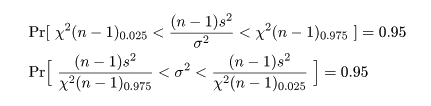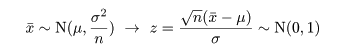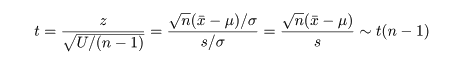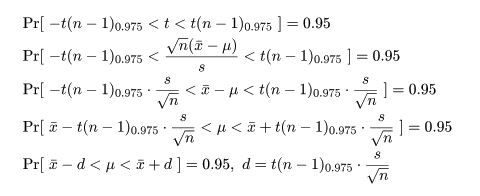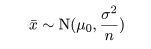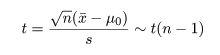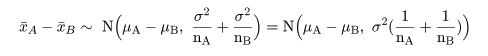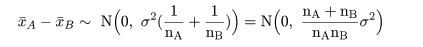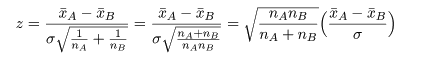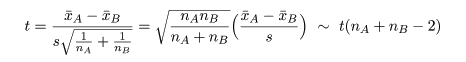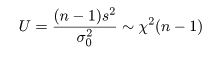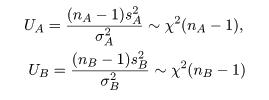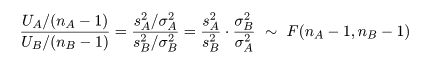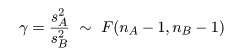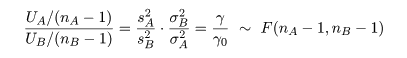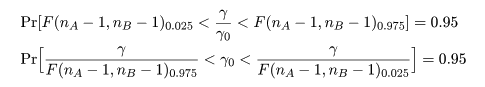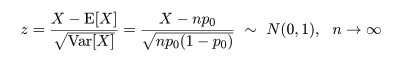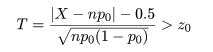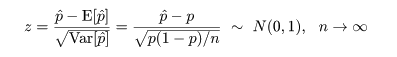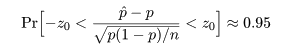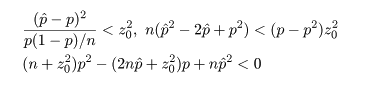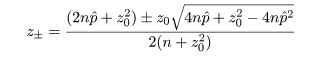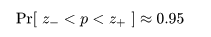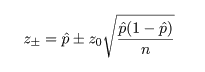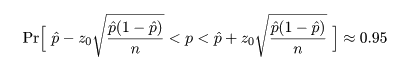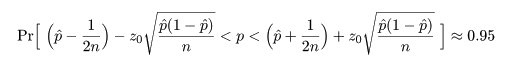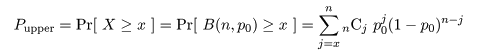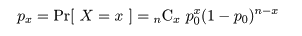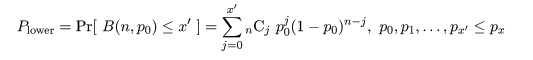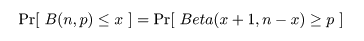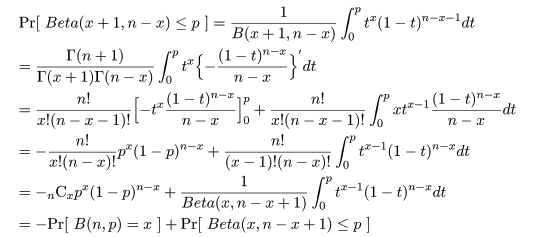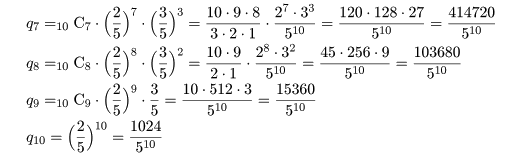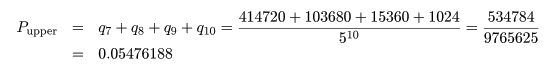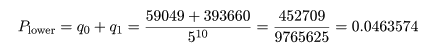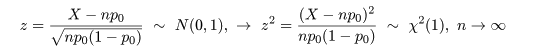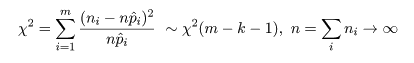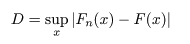統計特論3
5.分布パラメータの推定
統計的推定
母集団(population)分布の形がパラメータ(母数)θ をもった f(x;θ) であると
想定できる場合,母集団から大きさ n の無作為標本(random sample),
X1,…,Xn,
を抽出し,その標本から
母集団分布のパラメータ θ を推定する.
たとえば,母集団が正規分布すると想定される場合,母集団母数は平均 μ,分散 σ2 になる.すなわち,
θ = (μ,σ2)である.
統計量(statistic)
母集団からの無作為標本の任意の関数で未知のパラメータを含まない
ものを統計量という.これは,
T = t(X1,…,Xn)
(5. 1)
と表される.たとえば,標本平均,最大値,などである.標本の実現値であるデータや観測値(observation)
が与えられると,統計量の具体的な値が定まる.
点推定(point estimation)
分布パラメータ θ の値そのもの,もしくは,その関数 τ(θ) の値を推定することである.
θ を推定した量を θ^ と表記し,これを推定量(estimator)と
呼ぶ.推定量は確率変数の関数(推定関数)で,統計量で構成される.
標本の観測値が得られたときの推定量の実現値を推定値(estimate)
と呼んで区別することもある.
区間推定(interval estimation)
分布パラメータ θ が含まれる範囲を確率的に
Pr[ θ^1 < θ < θ^2 ] = p,
のように推定すること.
推定量には何でもなれる
分布の未知母数 θ の推定量としてはどのようなものもなりうる.極端な例では,どのような標本が得られた
かにかかわらず,母集団平均は1である,という推定方式や,
最初に得られた標本の値を母集団平均とする,という方式も考えられる.このような推定方式では,
母集団に対して有益な情報を与えることはほとんどないが,たまたま母集団母数を正確に推定することもある.
つまり,競馬の単勝馬券(1 着となる馬番号を当てる)で何も考えずに 3 番の馬券を買い続ければ,たまには
的中することもあるのと同じである.
このため,推定量の良さを測る尺度が必要になる.
一致推定量(consistent estimator)
母集団分布パラメータ θ は,母集団から標本 X1,…,Xn
を抽出して推定量 θ^ を構成する.このとき,
標本の大きさ n を大きくしていけば母集団母数 θ を正しく推定できることが必要であろう.つまり,
任意の ε > 0 に対して,
limn -> ∞ Pr[ | θ^ - θ | < ε ] = 1,
(5. 2)
が成り立つ.これは,データをたくさん集めればそれだけ母集団に対して正しい知識を
与える推定方法を行っていることを保証するものである.式(3.4)の大数の法則により,標本平均
X- = ΣXi/n
は母集団平均の一致推定量であることがわかる.
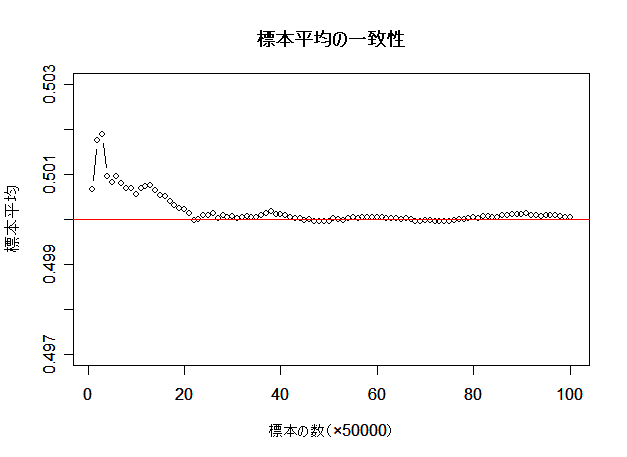
- 一様分布の標本平均の一致性
(0,1)一様分布から毎回 n = 500 の標本を抽出して追加し,標本平均を求める.回数を重ねるごとに
標本の大きさが n だけ増えていくので,標本平均が母集団平均 μ = 0.5 に近づく様子が観察されるはずである.
# 標本平均の一致性の R スクリプト
|
N <- 100
| # シミュレーション回数 |
|
n <- 50000
| # 1回のサンプルサイズ |
|
s <- 0
| # 乱数の和 |
|
q <- numeric(0)
| # 毎回の標本平均 |
|
for(i in 1:N){
| # |
|
s <- s + sum(runif(n))
| # 乱数の和をたす |
|
q <- c(q, s/(n*i))
| # 今回までの標本平均 |
|
}
| # |
|
plot(q, type="b", xlab="標本の数(×50000)", ylab="標本平均", ylim=c(0.497,0.503))
|
|
abline(h=0.5, col=2)
| # 真値のライン |
|
title(main="標本平均の一致性")
| # |
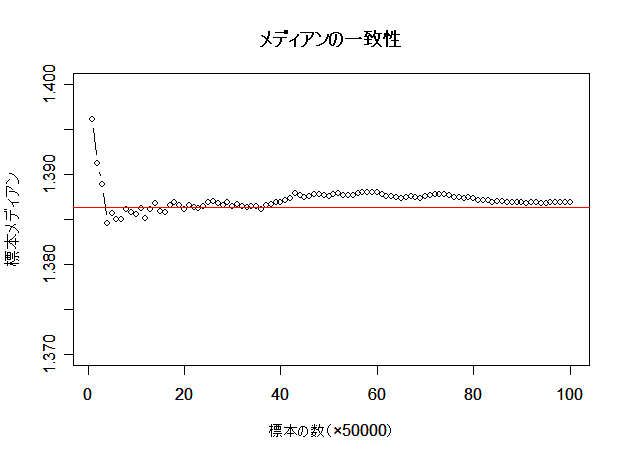
- χ2 分布の中央値の一致性
母集団分布のパラメータの他,分布の分位点も一致推定量である.すなわち,標本累積分布関数は標本の大きさ
を増加させれば母集団累積分布と一致すると考えられる.実際前節で,正規乱数2個の2乗和の分布は,自由度 2 の
χ2 分布によく一致していて,累積分布では違いがほとんどわからなかった.このため,メディアン
の値もよく一致していると考えられる.これより,母集団分布の任意の分位点に対して,標本分位点が一致推定量
になると考えられる.
# 分布の中央値の一致性の R スクリプト
|
N <- 100
| # シミュレーション回数 |
|
n <- 50000
| # 1回のサンプルサイズ |
|
s <- NULL
| # |
|
q <- NULL
| # |
|
for(i in 1:N){
| # |
|
s <- c(s, rchisq(n, 2))
| # χ2 分布乱数の追加 |
|
q <- c(q, median(s))
| # 乱数の中央値(メディアン) |
|
}
| # |
|
plot(q, type="b", xlab="標本の数(×50000)", ylab="標本メディアン", ylim=c(1.37, 1.4))
|
|
abline(h=qchisq(0.5, 2), col=2)
| # χ2 分布メディアンの真値 |
|
title(main="メディアンの一致性")
| # |
平均2乗誤差(Mean Squared Error : MSE)
推定量の良さを測る最も一般的な尺度である.分布パラメータ θ のある関数 τ(θ) を
統計量 T で推定したとき,平均2乗誤差は,T と τ(θ) との偏差の2乗の期待値
で表される.すなわち,

|
(5. 2)
|
と定義される.MSE は θ の関数であるが,どのような θ に対しても MSE が小さい
ような推定量 T があればよいが一般には存在しない.
一方,MSE は,
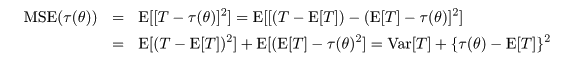
|
(5. 3)
|
と変形される.ここで,τ(θ) - E[T ] は推定量 T の偏り(バイアス(bias))と
呼ばれる量である.つまり,平均2乗誤差は,推定量の分散とバイアスの大きさに分解できる.
なお,推定量 T の分散 Var[T] の平方根を標準誤差(Standard Error : SE)と呼ぶこともある.
不偏推定量(unbiased estimator)
分布パラメータ θ のある関数 τ(θ) の推定量 T の中で,
E[T ] = τ(θ)
(5. 4)
となるものを不偏推定量という.
不偏推定量のクラスの中では,平均2乗誤差は推定量の分散 Var[T ] と等しくなるので,
分散最小の推定量が望ましいことになる.
Cramer - Rao の下限(Cramer - Rao lower bound)
不偏推定量のクラスで到達可能な分散の下限は,Cramer - Rao により与えられている.
いま,分布パラメータ θ のある関数 τ(θ) の不偏推定量 T の分散の下限は,

|
(5. 6)
|
で与えられる.ここで,I(θ) は,Fisher の情報量(Fisher information)である.
また,Cramer - Rao の下限に一致する分散をもつ不偏推定量を有効(efficient)と言う.
- 分散既知の正規分布母集団に対する標本平均の有効性
分散が σ02 と既知の正規母集団 N(μ,σ02) から
大きさ n の無作為標本 X1,…,Xn を抽出した.
標本平均 X- の分布は,
X- 〜 N(μ,σ02/n)
であり,もちろん,X- は不偏である.Cramer - Rao の分散の下限を求める.
正規分布密度関数 φ(x ;μ,σ02) の対数を,平均 μ で微分すると,
であるので,Fisher 情報量は
となる.τ'(θ) = μ' = 1,に注意すると, Cramer - Rao の分散の下限は,
1/(nI (θ) ) = σ02/n
となる.これは,標本平均 X- の分散に一致する.よって,標本平均は
分散既知の正規母集団の平均に対する有効な推定量,すなわち,最良であることがわかる.
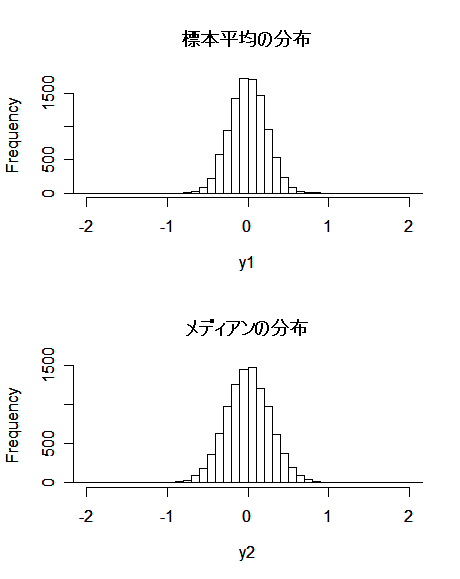
- 分散既知の正規母集団に対するメディアンの分散
分散が σ02 と既知の正規母集団 N(μ,σ02) から
大きさ n の無作為標本 X1,…,Xn を抽出した.
メディアン(中央値) M は漸近的(標本の大きさ n が大きくなるにつれて)に
M 〜 N(μ,πσ02/(2n))
の正規分布に従うことが知られている.すなわち,メディアン M は,標本平均 X- の分散
より π/2 ≒ 1.57 倍分散が大きい.推定量の標準偏差である標準誤差(SE)でいうと,
メディアンの標準誤差は標本平均の標準誤差の √π/2 ≒ 1.25 倍である.
このため,標本平均と同程度の標準誤差(精度)を得るには 1.57倍の標本が
必要になる.この値の逆数 2/π ≒ 0.637 を相対漸近効率と言う.正規母集団における
メディアンの(Cramer - Rao の下限に対する)有効性は 63.7%であるといえる.
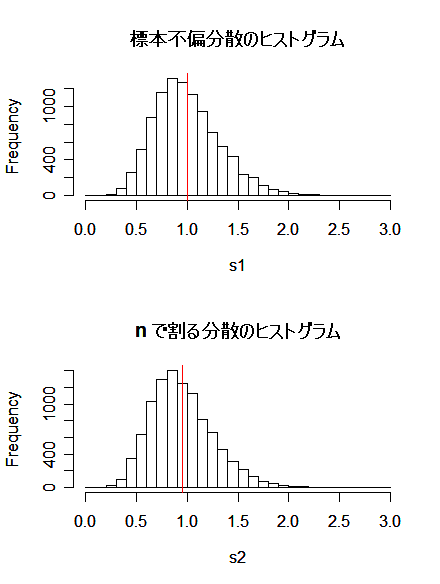
# メディアンの分散の R スクリプト
|
N <- 10000
| # シミュレーション回数 |
|
n <- 20
| # サンプルサイズ |
|
y1 <- NULL
| # |
|
y2 <- NULL
| # |
|
for(i in 1:N){
| # |
|
x <- rnorm(n)
| # 標準正規乱数 n 個 |
|
y1 <- c(y1, mean(x))
| # 標本平均列 |
|
y2 <- c(y2, median(x))
| # メディアン列 |
|
}
| # |
|
m1 <- mean(y1); m2 <- mean(y2)
| # 標本平均とメディアンの平均 |
|
s1 <- var(y1); s2 <- var(y2)
| # 標本平均とメディアンの分散 |
|
s2/s1
| # 分散比 |
|
sqrt(s1) | # 標本平均の標準誤差 |
|
sqrt(s2) | # メディアンの標準誤差 |
|
op <- par(mfrow = c(2, 1))
| # |
|
hist(y1, breaks=seq(-4,4, by=0.1), xlim=c(-2, 2), main="")
|
|
title(main="標本平均の分布")
| # |
|
hist(y2, breaks=seq(-4,4, by=0.1), xlim=c(-2, 2), main="")
|
|
title(main="メディアンの分布")
| # |
|
par(op)
| # |
|
 |
頑健(ロバスト)性(robustness)
データ(標本の実現値)が正規分布から由来するのであれば,母平均の推定量として標本平均が最小分散をもつ
不偏推定量なので,最良である.しかしながら,実際のデータが正規分布から由来するとは限らない場合もある.
このようなときや外れ値(outlier)があるときでもそれなりの推定が行える推定量をロバストである,という.
メディアンは,標本平均よりロバストであることが知られている.
いま,正規分布より裾の重い t 分布を考えてみる.母集団分布が t 分布であるときの標本平均とメディアンの
分布を比較すればロバスト性が評価できる.自由度 2 の t 分布では極端な値が出やすいので,標本平均の
分散はとても大きくなっている.
最尤法
分布パラメータの推定法として,最もよく用いられるのが最尤法である.
尤度(likelihood)
パラメータ θ をもった分布 f(x;θ) からの無作為
標本(random sample) X1,…,Xn が得られたとする.このとき,
標本の同時分布の確率密度は,
と表せる.これを,標本が与えられたときのパラメータ θ の関数とみなし,
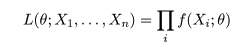
|
(5. 7)
|
と表記する.これを,標本 X1,…,Xn の尤度(関数)という.
尤度は積の形で少し扱いにくいので,尤度の対数を取った対数尤度
を用いることも多い.
最尤推定量(Maximum Likelihood Estimator : MLE)
標本の尤度は,標本が生成する確率モデル f(x;θ) のもとでの標本の同時確率密度
なので,想定した確率モデル f(x;θ) のもとで標本が生起する(データのような標本が実現する)
確率に比例した量になる.この標本の "生起確率" を最大にするような分布パラメータ θ を
求めることを最尤法という.最尤法により得られたパラメータの推定量を
最尤推定量という.
多くの場合,最尤推定量は尤度をパラメータ θ で微分して 0 とおいた,
の解,もしくは,対数尤度を θ で微分して 0 とおいた,
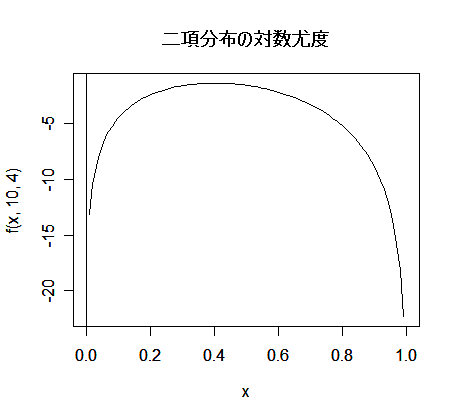
- 二項分布の成功確率の最尤推定
成功確率が p であるベルヌイ試行を n 回繰り返したところ成功回数が x であったとすると,その尤度と
対数尤度は,
となる.これを最大にする p を求めるため,p で微分して 0 とおくと,
となる.その解を p^ とおくと,
となり,最尤推定量が求まる.二項分布の場合の最尤推定量は解析的に簡単に求まるが,R では数値的に
最尤推定値を求めることができる.n = 10 回の試行で x = 4 回成功したとすると,成功確率 p の
最尤推定値は,p^ = x/n = 4/10 = 0.4 である.
# 二項分布の最尤推定値の R スクリプト
|
f <- function(x, n, y) y*log(x) + (n-y)*log(1-x)
| # 対数尤度を自分で定義 |
|
f <- function(x, n, y) dbinom(y, size=n, prob=x, log=T)
| # 二項分布確率関数の利用 |
|
curve(f(x, 10, 4), 0,1)
| # 対数尤度関数の表示 |
|
abline(h=0, v=0)
| # |
|
title(main="二項分布の対数尤度")
| # |
|
optimize(f, c(0.1, 0.9), maximum = T, n=10, y=4)
| # 対数尤度の最大値を取る点の探索 |
- 正規分布パラメータの最尤推定
平均 μ,分散 σ2 である正規分布 N(μ,σ2) からの無作為標本の実現値
x1,…,xn が得られたとすると,その尤度と
対数尤度は,
となる.これを最大にする μ と σ2 を求めるため,μ,σ2 で偏微分
して 0 とおくと,
となる.その解を μ^ と σ2^ とおくと,
となり,最尤推定量が求まる.正規分布の分散の最尤推定量は,標本不偏分散ではないことに注意.
なお,正規モデルのもとでの対数尤度の最大値は,対数尤度のパラメータにその最尤推定値を代入して,
と求められる.この式は,後に回帰モデルにおけるモデル選択のところで用いられる.
さてこのように,正規分布の場合の最尤推定量は解析的に簡単に求まるが,R では数値的に
最尤推定値を求めることができる.
# 正規分布の最尤推定値の R スクリプト
|
n <- 10
| # サンプルサイズ |
|
y <- rnorm(n)
| # サンプルとして正規乱数を使用 |
|
f <- function(x){
| # 正規分布対数尤度関数の定義 |
|
m <- x[1]; s2 <- x[2]
| # 平均と分散 |
|
sum(dnorm(y, mean=m, sd=sqrt(s2), log=T))
| # 正規分布密度関数の対数(log=T) |
|
}
| # |
|
a <- optim(c(0.1,0.9), f, control=list(fnscale=-1, ndeps=1e-5))
| # 平均と分散の初期値で f を最大化(fnscale=-1) |
|
a$par
| # 最尤推定値(近似解)の表示 |
|
mean(y)
| # 平均の最尤推定値(真値) |
|
var(y)*(n-1)/n
| # 分散の最尤推定値(真値) |
|
m <- seq(-1, 1, length=50)
| # 平均の範囲指定 |
|
s2 <- seq(0.5, 2, length=50)
| # 分散の範囲指定 |
|
z <- matrix(0, nrow=length(m), ncol=length(s2))
| # (平均,分散)の行列 |
|
for(i in 1:length(m)){
| # |
|
for(j in 1:length(s2)) z[i,j] <- f(c(m[i],s2[j]))
| # 対数尤度値を z に格納 |
|
}
| # |
|
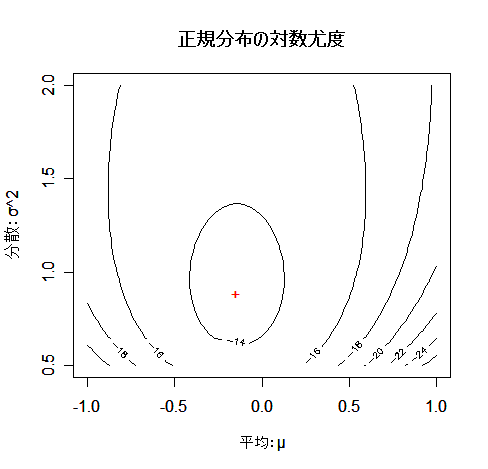
contour(m, s2, z, xlab="平均:μ", ylab="分散:σ^2")
| # 対数尤度の等高線表示 |
|
points(a$par[1], a$par[2], pch="+", col=2)
| # 最尤推定値の数値解の表示 |
|
title(main="正規分布の対数尤度")
| # |
- カウント数データの尤度
カウント数データを生成する離散確率分布がパラメータを θ として,f(x ; θ) で表されるとする.
カウント数
x = 0,1,2,…,r,に対して以下の表のようなデータが得られたとする.ただし,x = r + 1 に対しては,
r + 1 以上のカウント数が得られた場合を集計している.このようなデータを打ち切り(censored)データ
という.すなわち,r + 1 以上のカウント数は出現頻度が低いので,一括してまとめられたものである.
打ち切りデータは,生存期間など,対象となる生物個体すべてが死亡するまで観測しないで,ある程度の
期間観測した後,それ以降は,観測終了時の生存個体数を記録して観測を打ち切るような場合に生じる.
カウント数データ
| カウント数 x |
0 |
1 |
2 |
… |
r |
r + 1 以上 |
| 観測度数 y |
n0 |
n1 |
n2 |
… |
nr |
nr+1 |
上の表を生成するカウントデータ y = (5,1,3,0,…) が得られたとすると,その尤度は,
と表せる.ここで,最後の項は n ≧ r + 1 以上のカウントが得られる確率を足し合わせた確率が nr+1 回
生起したと考えて計算される尤度である.これより対数尤度は,
と表せる.これを最大にする θ を求めればよい.
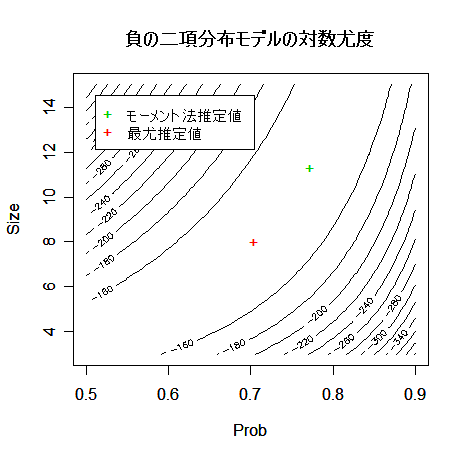
- 負の二項分布パラメータの最尤推定
負の二項分布の紹介時に,
において,虫歯数データ
小学生1人あたりの虫歯数(再掲だが少し違う)
| 虫歯の数 |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8以上 |
| 児童の数 |
4 | 9 |
16 | 13 |
9 | 7 |
5 | 4 |
3 |
に,モーメント法でパラメータを推定して負の二項分布をあてはめた.
虫歯 8 以上を 8 とみなしてデータの平均を m = 3.3286,分散を v = 4.3063 と計算した.負の二項
分布の平均と分散がデータの平均と分散と等しいと考え,
平均:n(1 - p)/p = m,分散:n(1 - p)/p2 = v
とおいた.これより,p = m/v = 0.7729,n = mp/(1 - p) = 11.3315,
と推定された.
ここでは,モーメント法による推定値を初期値として,パラメータの最尤推定を行って
みる.
# 負の二項分布の最尤推定値の R スクリプト
|
y <- c(4,9,16,13,9,7,5,4,3)
| # 虫歯データ |
|
xx <- 0 : (length(y) - 1)
| # 虫歯数 |
|
s <- sum(y)
| # |
|
m <- sum(xx*y/s)
| # 虫歯数平均 |
|
v <- sum((xx-m)^2*y/s)
| # 虫歯数分散 |
|
p0 <- m/v
| # 確率パラメータ(モーメント法) |
|
n0 <- m*p0/(1-p0)
| # サイズパラメータ(モーメント法) |
|
f <- function(x){
| # |
|
n <- x[1]; p <- x[2]
| # |
|
if(p<0) p <- 0.01
| # p が負のとき |
|
if(p>1) p <- 0.99
| # p が1を超えたとき |
|
r <- length(y)-2
| # |
|
q <- dnbinom(0:r, size=n, prob=p, log=T)
| # 負の二項分布の確率の対数 |
|
q[r+2] <- pnbinom(r, size=n, prob=p, lower.tail=F, log.p=T)
| # 負の二項分布 r 以上の確率の対数 |
|
sum(q*y)
| # カウント数の負の二項分布の対数尤度 |
|
}
| # |
|
a <- optim(c(n0, p0), f, control=list(fnscale=-1))
| # 対数尤度の最大値探索 |
|
a$par
| # 最尤推定値 |
|
p <- seq(0.5, 0.9, length=51)
| # 確率パラメータの離散値範囲 |
|
n <- seq(3, 15, length=51)
| # サイズパラメータの離散値範囲 |
|
z <- matrix(0, nrow=length(p), ncol=length(n))
| # 対数尤度値の格納行列 |
|
for(i in 1:length(p)){
| # |
|
for(j in 1:length(n)) z[i, j] <- f(c(n[j], p[i]))
| # 対数尤度値の格子点での計算 |
|
}
| # |
|
contour(p, n, z, xlab="Prob", ylab="Size")
| # 等高線表示 |
|
points(a$par[2], a$par[1], pch="+", col=2)
| # 最尤推定値の表示 |
|
points(p0, n0, pch="+", col=3)
| # モーメント推定値の表示(初期値) |
|
legend(0.51, 14.5, c("モーメント法推定値","最尤推定値"), bg="white", pch="+", col=3:2)
|
|
title(main="負の二項分布モデルの対数尤度")
| # |
6.正規母集団からの標本に基づく推論
独立な正規分布の合成分布
平均 μ1,
分散 σ12,の正規分布
からの標本 X 〜
N( μ1,σ12 )
と,
平均 μ2,
分散 σ22,の正規分布
からの標本 Y 〜
N( μ2,σ22 )
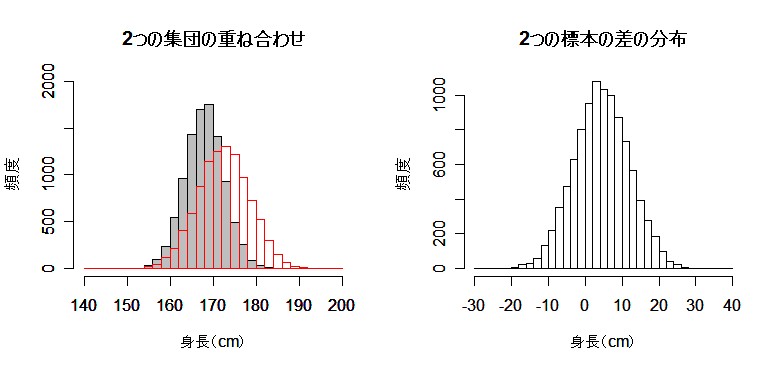
があり,両者が互いに独立であるとする.(Y の値は X の値の影響を受けない.)
正規分布に基づく母数の区間推定
正規分布は,平均 μ と分散 σ2 の2つの母数を持つ.
2つの母数とも未知であるのが普通であるが,片方が既知であるときは母数に関する推論は
簡単に行える.このため,多少非現実的な設定であるが,まず,既知の場合を考え,その後,より
一般的である2つの母数とも未知である場合を扱う.
分散既知の場合の母平均 μ の区間推定
正規分布する母集団で母分散 σ2
がわかっている場合は,未知の母平均 μ に関する区間推定は以下のように行える.
いま,正規分布 N( μ,σ2 ) において,大きさ n の標本
x1,x2,…,xn
を抽出したとき,母平均は標本平均で推定される.標本平均 x- の分布は,
となる.標準正規分布の 97.5%分位点を z0.975(= 1.96)とすると,
標準正規分布する確率変数 z が -z0.975 から z0.975 に入る
確率は 0.95 となる.つまり,
となる.最後の式を母集団平均 μ の 95% 信頼区間(confidence interval)と言う.
このように,母数の信頼区間を標本から推定することを区間推定という.区間推定においては,
信頼区間の幅 2d が小さい程よい.すなわち,母分散が小さい母集団で,
標本の大きさ(サンプルサイズ)が大きい程,精度の高い推定が行える.
- 95% の意味
同じ正規母集団から標本抽出を繰り返すと,毎回標本平均として異なる値がえられ,それに
対応して信頼区間も異なる.この信頼区間の 95% が真の平均 μ を含む,という意味である.
つまり,100回の標本抽出により,100 個の信頼区間を作ったら平均的にみて,95 個の信頼区間が
真の平均 μ を含むことが期待できる.
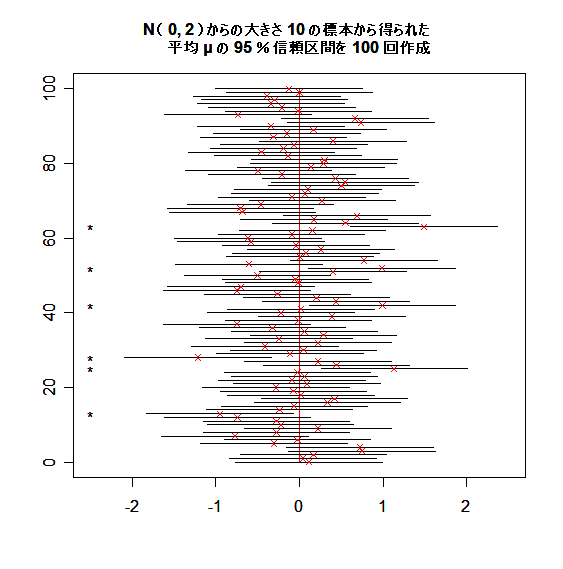
下の図は,平均 0 分散 2 の正規分布 N( 0, 2 ) から大きさ 10 の標本を取りだし,分散が既知であるとして,
母平均に対する信頼区間を 100 個生成したものである."×" が標本平均を示す.左の "*" は,信頼区間
が母平均の真値 0 を含まなかった場合である.
# 平均 μ の 95 %信頼区間 100 回生成の R スクリプト
|
v <- 2; n <- 10
| # 母分散と標本の大きさ |
|
d <- qnorm(0.975)*sqrt(v/n)
| # 95%信頼区間の幅 |
|
x <- c(-2.5, -2.5, 2.5, 2.5)
| # グラフの x の範囲 |
|
y <- c(0, 100, 100, 0)
| # グラフの y の範囲 |
|
plot(x, y, type="n", xlab="", ylab="")
| # グラフ領域確保 |
|
segments(0, 0, 0, 100, col="red")
| # 母平均のライン |
|
for(i in 0:100){
| # 100回の繰り返し |
|
r <- rnorm(n, mean=0, sd=sqrt(v))
| # N(0, v)からの大きさ n の標本平均 |
|
m <- mean(r)
| # 標本平均 |
|
segments(m-d, i, m+d, i)
| # 信頼区間の表示 |
|
points(m, i, pch=4, col="red", cex=0.8)
| # 標本平均の赤×表示 |
|
if(m-d>0 || m+d<0) text(-2.5, i, "*")
| # 信頼区間が母平均を含まない(失敗)した場合 |
|
}
| # |
|
title(main="N( 0, 2 )からの大きさ 10 の標本から得られた
| |
|
平均 μ の 95 %信頼区間を 100 回作成", cex.main=1.0)
| # |
平均既知の場合の母分散 σ2 の区間推定
正規母集団で母平均 μ がわかっているとき,大きさ n の標本
x1,x2,…,xn
を抽出したとき,母分散は,
で推定される.ところで,標本は
と分布するので,自由度 n の χ2 の 2.5%分位点と 97.5%分位点をそれぞれ,
χ2(n)0.025,χ2(n)0.975 とすると,
が成り立つ.下の式の区間を母分散 σ2 の 95%
信頼区間と言う.
平均未知の場合の母分散 σ2 の区間推定
正規母集団では,母数が未知であるのが普通であろう.このとき,
大きさ n の標本
x1,x2,…,xn
を抽出したとき,母平均 μ と母分散 σ2 は,そえぞれ
標本平均 x- と標本分散 s2,
で推定される.母平均 μ の信頼区間を述べる前に母分散 σ2 の
信頼区間の構成法を述べる.
ところで,標本や標本平均は,
と分布する.一方,
と計算されるので,(n - 1)s2/σ2 という量は,
と,自由度 n - 1 の χ2 分布,χ2(n - 1),に従うことがわかる.
自由度 n - 1 の χ2 分布の 2.5%分位点と 97.5%分位点をそれぞれ,
χ2(n - 1)0.025,χ2(n - 1)0.975 とすると,
が成り立つ.下の式の区間を母分散 σ2 の 95%
信頼区間と言う.
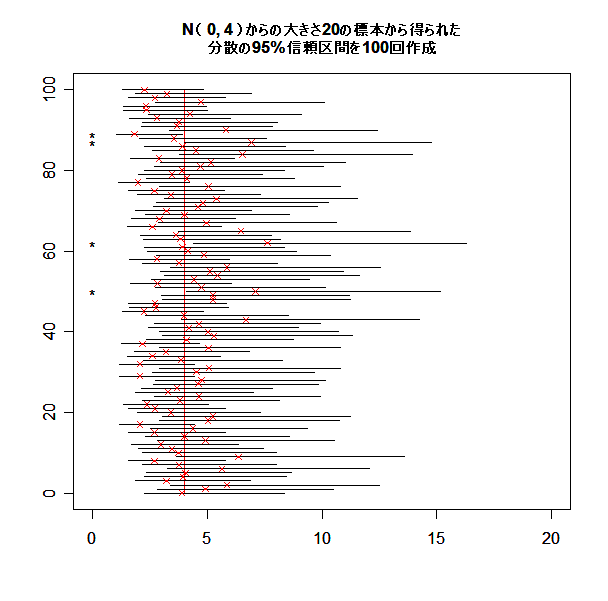
- 母分散 σ2 の 95%信頼区間
母平均が未知のときの母分散 σ2 の 95%信頼区間を,
母平均に対する信頼区間と同様に100回作ってみる.
# 母分散 σ2
の 95 %信頼区間 100 回生成の R スクリプト
|
m <- 20; v <- 4
| # 正規母集団の平均と分散 |
|
n <- 20
| # 標本の大きさ |
|
x <- c(0, 0, 20, 20)
| # グラフの x の範囲 |
|
y <- c(0, 100, 100, 0)
| # グラフの y の範囲 |
|
plot(x, y, type="n", xlab="", ylab="")
| # グラフ領域確保 |
|
segments(v, 0, v, 100, col="red")
| # 母分散のライン |
|
for(i in 0:100){
| # 100回の繰り返し |
|
r <- rnorm(n, m, sqrt(v))
| # 母集団からの無作為標本 |
|
s <- (n-1)*var(r)
| # 標本の偏差平方和 |
|
s1 <- s/qchisq(0.975, df=n-1)
| # 95 %信頼区間の下限 |
|
s2 <- s/qchisq(0.025, df=n-1)
| # 95 %信頼区間の上限 |
|
segments(s1, i, s2, i)
| # 信頼区間の表示 |
|
points(var(r), i, pch=4, col="red", cex=0.8)
| # 標本分散の赤×表示 |
|
if(s1 > v || s2 < v) text(0, i, "*")
| # 信頼区間が母分散を含まない(失敗)した場合 |
|
}
| # |
|
title(main="N( 20, 4 )からの大きさ20の標本から得られた
|
|
分散の95%信頼区間を100回作成", cex.main=1.0)
| # |
分散未知の場合の母平均 μ の区間推定
前節で考えたように正規母集団の母数が未知のときは,
大きさ n の無作為標本
x1,x2,…,xn
から,母平均 μ と母分散 σ2 は,それぞれ
標本平均 x- と標本分散 s2,
で推定される.
標本平均 x- の分布は標準化すると,
のように標準正規分布となり,標本分散に関係する量は,
のように自由度 n - 1 の χ2 分布する.これより,z と U をその自由度 n - 1 で
割った量の平方根との比は,
のように自由度 n - 1 の t 分布に従う.
自由度 n - 1 の t 分布の 97.5%分位点を t(n - 1)0.975 とすると,
t 分布する確率変数 t が -t(n - 1)0.975 から t(n - 1)0.975 に入る
確率は 0.95 となる.つまり,
となる.最後の式を母分散未知のときの母集団平均 μ の 95% 信頼区間と言う.
- 課題:
母分散既知のときの母集団平均 μ の 95% 信頼区間100回生成の R スクリプトを参考にして,
母分散未知のときの母集団平均 μ の 95% 信頼区間を100回生成し,母分散が未知と既知で
信頼区間にどのような違いがあるか考えよ.
7.仮説検定(Test of hypothesis)
帰無仮説(H0)と対立仮説(H1)
統計学で扱う仮説(hypothesis)とは,母集団に対する断定や推測.たとえば,
- 母集団は正規分布に従っている.
- 母集団平均は 0 である.
- 母集団 A と母集団 B の平均は等しい.
などである.
統計的仮説検定で用いられる仮説は,まず,帰無仮説(null hypothesis)という形式で与えられる.
帰無仮説は棄却(reject)されることに意味がある仮説である.
帰無仮説と反対の仮説を対立仮説(altanative hypothesis)という.
上の3番目の例でみると,
帰無仮説:
母集団 A と母集団 B の平均は等しい.
(H0: μA = μB)
対立仮説:
母集団 A と母集団 B の平均は等しくない.
(H1: μA ≠ μB)
母集団 A と母集団 B は異なる処理(薬の投与など)をしているので,実験の目的
は,母集団 A と母集団 B の平均は異なる(処理効果がある)ことを言いたい
(対立仮説が正しいことを望む)のだが,まずは
「等しい(処理効果無し)」と仮定してみようという考え方で,
数学の背理法と似た論理である.
背理法:√2 が無理数であることを証明するため,まず√2 が有理数であると仮定し,矛盾があることを
示す.つまり,有理数であることは絶対ありえない(確率 0 である!)ことを示す.
この矛盾は,そもそも√2 を有理数とした仮定が誤っていたからであると考え,有理数という仮定を
棄却して,無理数であることを証明する.
検定の概要
検定統計量(Test statistic)
標本から算出される量で,検定に用いられるもので,t 値(t value),F 値(F value)などがある.
この値から帰無仮説を受託(accept)(採択)するか
棄却(reject)(対立仮説の採択)するかを判定する.
p 値(p value)と有意水準(Significance level)
統計的仮説検定では,たとえば2つの母集団平均が等しいという帰無仮説を考えると,
この帰無仮説のもとで,検定統計量(標本平均の差に基づく t 値など)以上
(もしくは未満)の値が得られる確率を求める.R ではこの値が p 値で表示される.
p 値は
くだけた言い方をすれば,帰無仮説が正しいとしたときに,標本のようなデータが得られる確率
である.
これが十分小さい(ほとんどありえない)ときは,平均が等しいと仮定したことが誤りであったと判断して
帰無仮説を棄却し,2つの母集団平均には差があると結論づける.
この確率がそれほど小さく
ない場合は,このような統計量が得られることもありえると考え,帰無仮説を採択し,平均が等しいと考え
てもよいとする.
棄却か採択かの判断の基準となる確率を有意水準といい,
5 % や 1 % がよく用いられる.
統計のソフトが発達していなかった頃は,検定統計量である t 値や F 値を電卓等で算出し,その値を
t 分布や F 分布の 5 %や 1 %の有意水準に対応する数表と照らし合わせて検定を行い,5 %有意とかを
記述していた.
現在では,ソフトが検定統計量に対する p 値を直接計算してくれるので数表はいらなくなった.この結果,
検定に重要な数字であった t 値や F 値より,より直接的な p 値が重要な指標になってきた.p 値を
みれば,何%有意かが一目でわかるので,結果にわざわざ 5 %有意とかを記述する必要がなくなってきており,
論文の書き方も変わってきている.
片側検定と両側検定
実験状況によっては,薬投与などの処理を行った集団(処理群)平均
μA が,薬を投与しない
集団(対照群)の平均 μB より小さくなることはないことが事前に
わかっているような場合が
ある.このようなとき,
帰無仮説,H0: μA =
μB
対立仮説,H1: μA >
μB
となる.これは,事前情報より,μA < μB となる可能性
をまったく考えない場合である.
このため検定には,片側 5 %点や 1 %点を用いる.
両側検定と信頼区間
母集団平均に対する両側検定は,母集団平均に対する信頼区間と大きな関係がある.
いま,帰無仮説(H0)と対立仮説(H1)が,
H0:μ = μ0
H1:μ ≠ μ0
であり,母分散 σ2 が既知のときを考える.
標本の大きさがnで,標本平均が x- であったとすると,母平均μに対する
95%信頼区間は,
Pr[ − 1.96 < √n(x-
− μ )/σ < 1.96 ] = 0.95,
Pr[ x- − 1.96×σ/ √n < μ
< x- + 1.96×σ/ √n ] = 0.95
となる.
一方,この検定の検定統計量は,標本平均の標準化値の絶対値
|z| = √n|x-
− μ0 |/σ
で,
有意水準 5 %で帰無仮説を受諾するのは,検定統計量 |z|
が両側 5 %点である 1.96 以下のときである.つまり,
帰無仮説を受諾 ⇔ − 1.96 < √n(x-
− μ0 )/σ < 1.96
である.この両者の関係より,
帰無仮説を受諾 ⇔ 母平均の信頼区間に μ0 が含まれる.
帰無仮説を棄却 ⇔ 母平均の信頼区間に μ0 が含まれない.
が成り立つ
検定における2種類の過誤
検定は,仮説を棄却するか採択するかのいずれかであるが,
統計量は分布をもつので,この判定には間違いが起こることがある.
以下のように,この過誤には
2 種類がある.
統計的検定における2種類の過誤
| |
仮説の棄却(reject) |
仮説の採択(accept) |
| 仮説が真(true)のとき |
第1種の過誤(Type 1 error) |
正解 |
| 仮説が偽(false)のとき |
正解 |
第2種の過誤(Type 2 error) |
第1種の過誤が有意水準である.また,第2種の過誤の確率を β としたとき,
仮説が偽のとき正しく仮説を棄却する確率,1 - β,を検出力,もしくは検定力(power)という.
よい検定は,第1種の過誤を固定したもとで検出力の高い検定方式である.
正規母集団の母平均に対する t 検定
1つの母集団に対する検定(One sample problem)
平均 μ,分散 σ2 がともに未知である正規母集団に対して,
帰無仮説 H0: μ = μ0
対立仮説 H1: μ ≠ μ0
の両側検定を考える.
いま,母集団から大きさ n の無作為標本
x1,x2,…,xn
を抽出したところ,標本平均が x-,標本分散が s2 であったとする.
帰無仮説のもとでは,標本平均は,
と分布するので,これを,標本平均の標準誤差 s/√n で標準化した t は,
のように自由度 n - 1 の t 分布に従う.この分布の97.5%分位点を t(n - 1)0.975 とすると,
有意水準 5 %の検定は,
|t| > t(n - 1)0.975
のとき帰無仮説を棄却する.|t| が検定統計量で,この値を |t| 値という.
なお,この検定は,対のある標本に適用できる.対のある標本とは,n 組のペアー標本(paired smple),
(x1,y1 ),(x2,y2 ),
…,(xn,yn )
からなる.正規性の仮定のもとでは,
xi 〜 N( μi,σx2 ),
yi 〜 N( μi + δ,σy2 )
ここで興味ある母数は δ であり,μ1,…,μn は攪乱母数(nuisance parameter)
である.yi と xi の差を取ると,
zi = yi − xi →
zi 〜 N( δ,σz2 )
となるので,1つの母集団に対する検定に帰着する.なおこの問題は,
反復のない 2×n の2元配置と考えて解くこともできる.
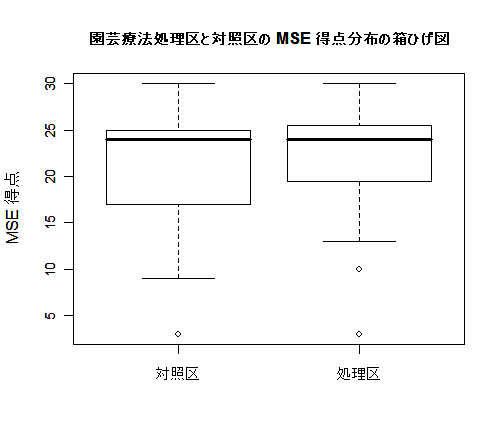
- 園芸療法前後での MSE 得点
園芸療法(horticultural therapy)は第2次大戦後,兵士のリハビリテーション等を通して欧米で発達してきた.
日本でも90年代から身体障害者,精神障害者,高齢者等の生活の質(QOL, Quality Of Life)や
セルフエスティーム(self-esteem,自尊感情)を向上させる手段として注目されてきていている.
園芸療法の数値的・客観的な効果の計測を行うため,認知症診断に用いられる
MSE(Mental State Examination,心理機能検査),CDT(Clock Drawing Test,時計描画テスト)と
老年者や認知症患者の日常生活の遂行能力を測る NM スケール(N 式老年者精神状態評価尺度),
N-ADL(N 式老年者日常生活動作能力評価尺度),および,気分の状態(抑うつ,活気のなさ,怒り,疲労,緊張,
混乱)を計測する POMS(Profile Of Mood State),自己記入式 QOL 質問表 QUIK を用いた.
これらの調査を園芸療法の前後でクライアントに対して行い,効果の数値的計測を行った.
ここでは,MSE の結果についての解析を行う.MSE は 30 点満点で,点数が高いほど日常生活に適応して
いると考えられている.MSE に関しては前後とも回答したクライアントの総数は 19 例であった.
データは下の表にまとめられている.このデータを用いて,園芸療法
を施す前と後では,心理機能に差がないという帰無仮説,すなわち,
H0:差 = 0
の検定を行う.
データダウンロード
文献
- 鈴木修(編),大森宏,児玉良治,渡辺俊之,矢野広,山根健治(2004).
専修学校における園芸療法士教育育成システムの研究開発
(文部科学省委託平成15年度「専修学校先進的教育研究開発事業」)
- 鈴木修,渡辺俊之,矢野広,山根健治,大森宏,伊東正信,最上正秀,山下容子,小泉力,
児玉良治,頭士智美,細井薫,水口聡子,遠藤久子,樋田奈穂子,小島ユリ,郡司敏幸(2005).
福祉サービス提供者に対する園芸療法教育システムの研究開発
(平成16年度文部科学省「専修学校社会人キャリアアップ教育推進事業」)
# 1つの母集団に対する t 検定の R スクリプト
|
engei <- read.csv("engei.csv")
| # csv データ読み込み |
|
engei
| # データの表示 |
|
x <- engei[,3]
| # 園芸療法前の MSE 得点を x に格納(列数で指定) |
|
x <- engei$療法前
| # 園芸療法前の MSE 得点を x に格納(変数名で指定) |
|
y <- engei$療法後
| # 園芸療法後の MSE 得点を x に格納(変数名で指定) |
|
t.test(y, x, paired=TRUE)
| # 1母集団 t 検定,paired = TRUE で対標本を指定 |
|
d <- y - x
| # 療法後 − 療法前で療法の効果をみる |
|
d
| # 療法の効果の表示 |
|
t.test(d)
| # 1母集団 t 検定,先ほどと同じ検定 |
|
n <- length(d)
| # 標本の大きさ(サンプルサイズ) |
|
mean(d)
| # 標本平均 |
|
sd(d)
| # 標本標準偏差 |
|
dv <- n - 1
| # 標本の自由度 |
|
t <- sqrt(n)*mean(d)/sd(d)
| # 効果がないとの帰無仮説のもとでの t 値 |
|
t
| # 検定統計量 t 値の表示 |
|
2*(1 - pt(t, df=dv))
| # 両側検定の p 値 |
|
t0 <- qt(0.975, df=dv)
| # 両側 5 %検定の閾値 |
|
dw <- t0*sd(d)/sqrt(n)
| # 95%信頼区間の幅 |
|
mean(d)-dw
| # 95%信頼区間の下限 |
|
mean(d)+dw
| # 95%信頼区間の上限 |
|
t.test(d, alternative="greater")
| # 片側検定 |
このデータでは,クライアント全体では園芸療法の効果は認められなかった.また,MSE の満点が30点なので,
元々心理機能に問題がなく満点近い得点のクライアントでは,効果が認められないのも当然といえる.
その上,園芸療法処方の前後で半年
程度のタイムラグがあるので,何もしなくても認知症の症状が進行する場合もあり,効果が検出しずらい
こともある程度予測できる.
課題:
クライアントのうち若年層( 85 歳以下)を取り出し,園芸療法の効果を検定せよ.
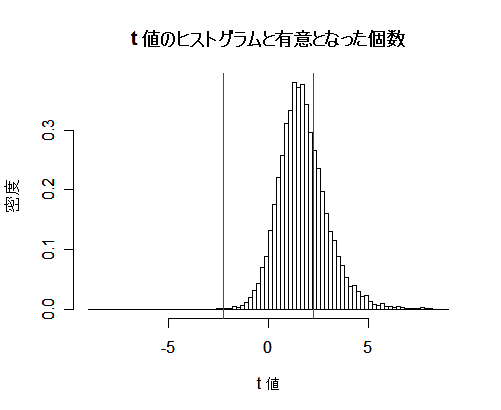
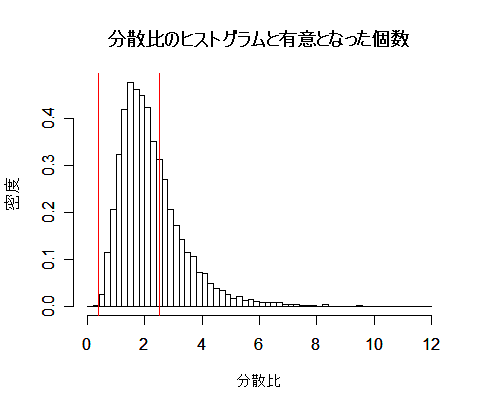
- t 検定の有意水準
t 検定の有意水準をシミュレーションにより確認してみる.
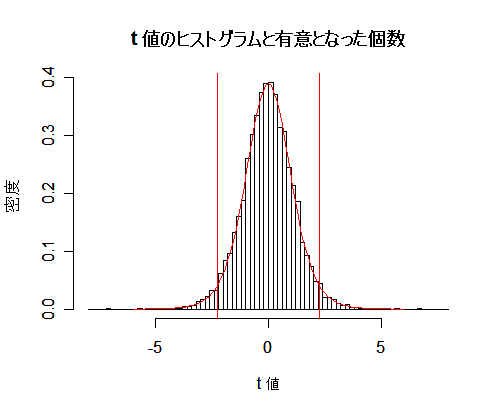
平均 μ = 10,分散 σ2 = 4 の正規分布から大きさ n = 10 の標本を抽出し,
その標本平均 x- と標本(不偏)分散 s2 から t 値を計算する.
これを N = 10000回繰り返すと,t 値のヒストグラムができる.このヒストグラムは自由度 9 の
t 分布に従っているはずである.
帰無仮説,H0:μ = 10
の検定では,
t 値の絶対値 |t| が
自由度 9 の t 分布の97.5%分位点 t(9)0.975 より大きくなった場合に棄却される.
このため,この個数を数えれば第1種の過誤の確率,つまり有意水準がシミュレーションにより推定できる.
N = 10000回のシミュレーションでは,これがほぼ 5 %になっていた.
#t 検定の有意水準 の R スクリプト
|
N <- 10000
| # シミュレーション回数 |
|
n <- 10
| # サンプルサイズ |
|
n1 <- rnorm(N*n, mean=10, sd=2)
| # N(10, 4) から大きさ n の標本を N 回シミュレーション |
|
n1.mat <- matrix(data=n1, ncol=n)
| # データ行列 |
|
n1.mean <- apply(n1.mat, 1, mean)
| # 各サンプルの平均 |
|
n1.var <- apply(n1.mat, 1, var)
| # 各サンプルの分散 |
|
n1.var3 <- n1.var/n
| # 各標本平均の分散 |
|
n1.td <- (n1.mean - 10)/sqrt(n1.var3)
| # 各サンプルの t 値 |
|
mean(n1.td)
| # t 値の平均 |
|
sd(n1.td)
| # t 値の標準偏差 |
|
mt <- ceiling(max(abs(n1.td)))
| # t 値の絶対値の最大値 |
|
xq1 <- qt(0.025, df = (n-1))
| # t(9) の 2.5% 点 |
|
xq2 <- qt(0.975, df = (n-1))
| # t(9) の 97.5% 点 |
|
length( n1.td[abs(n1.td) > xq2])
| # 5% 検定で有意となった個数 |
|
hist(n1.td, breaks=seq(-mt, mt, by=0.2), probability=TRUE, xlab="t 値", ylab="密度", main="")
|
|
abline(v=xq1, col="red")
| # 採択域の下限 |
|
abline(v=xq2, col="red")
| # 採択域の上限 |
|
#curve(dt(x, df=(n-1)), -6, 6, add=T, col="red")
| # t(9) の表示 |
|
title(main="t 値のヒストグラムと有意となった個数")
| # タイトル |
- t 検定の検出力(power)
前節では帰無仮説が真のとき,t 検定により仮説が棄却する確率を求めた.では,帰無仮説が偽であるとき,
帰無仮説がどれくらいの確率で正しく棄却できるであろうか.すなわち,t 検定の検出力はどの程度であろうか.
この問題に解析的に答えるのは難しいが,シミュレーションなら簡単に求めることができる.
いま,母集団の平均を m = 11 として,N(11,4) から大きさ n = 10 の標本を抽出する.
帰無仮説が偽であるとき,標本から得られる t 値の分布は簡単ではないが,N = 10000回のシミュレーション
を行えば t 値のヒストグラムが得られる.シミュレーションで得られた t 値の中で帰無仮説が棄却される割合
を求めれば検出力が推定できる.
シミュレーションの結果では,検出力は約 30 %であった.
#t 検定の有意水準 の R スクリプト
|
m <- 11
| # 母集団平均(帰無仮説が偽の場合) |
|
n1 <- rnorm(N*n, mean=m, sd=2)
| # N(m, 4) から大きさ n の標本を N 回シミュレーション |
課題:母集団平均を m = 12 としたときの検出力を求めよ.
レポート3::母集団平均 m の値を帰無仮説の母平均 μ0 = 10 から
小刻み(0.1程度)に動かして検出力をシミュレーション
により推定することにより,標本の大きさが n = 10 のときの検出力のグラフを m に対して描け.
これを検出力関数(power function)という.また,
同様にして標本の大きさ(サンプルサイズ)が n = 20 と n → ∞ のときの
検出力関数を描け.この検出力関数のグラフから検出力が 80%となるときの母集団平均 m の値を,
サンプルサイズが n = 10,20,∞ のときそれぞれで求めよ.
2つの母集団に対する検定(Two sample problem)
2つの母集団 A,B があり,それぞれが平均を μA,μB,
分散を σA2,σB2 の正規分布に従って
いるが,その値は未知であるとする.いま,両集団の分散の値が等しく,
σA2=σB2=σ2,と仮定
できるとしよう.このとき,2つの母平均に対する
帰無仮説,H0: μA =
μB
対立仮説,H1: μA ≠
μB
の検定は t 分布を用いて行える.
母集団 A から大きさ nA,母集団 B から大きさ nB の標本を抽出した.
母集団 A からの標本の標本平均が x-A,
標本分散が sA2 であり,母集団 B の
標本平均が x-B,
標本分散が sB2 であった.母集団 A,B が共通の
分散 σ2 をもつとすると,その推定値 s2 は
以下のように推定できる.
|
母集団 A からの標本の偏差平方和:
|
SA=(nA−1)sA2
|
|
母集団 B からの標本の偏差平方和:
|
SB=(nB−1)sB2
|
|
母集団 A,B 全体での偏差平方和:
|
S = SA + SB
=(nA−1)sA2+
(nB−1)sB2
|
|
母集団 A,B 共通の標本分散:
|
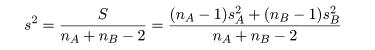
|
また,母集団Aの標本分布は,N(μA,σ2)であり,母集団Bでは,
N(μB,σ2)であることから,それぞれの標本平均は,
x-A 〜 N(μA,σ2/nA),
x-B 〜 N(μB,σ2/nB)
と分布する.これより,標本平均の差x-A−
x-Bは,
と分布する.
帰無仮説(H0: μA =
μB)のもとでは,μA−μB=0,なので,
標本平均の差は,
と分布する.これを標準化した z 値,
において,標準偏差 σ の代わりに標本標準偏差 s を代入した t 値が,
のように自由度 nA+nB−2 の t 分布に従うことを利用して検定ができる.
なお,母集団 A,B からの標本の大きさがともに等しく,
nA=nB=n であるときは,式がずっと簡単になる.
母集団A,Bで分散の同等性が疑われるときは,ウェルチ(Welch)の検定を用いる.
正規母集団の母分散に対する検定
母集団分散の検定
平均 μ,分散 σ2 がともに未知である正規母集団に対して,
帰無仮説 H0: σ2 = σ02
対立仮説 H1: σ2 ≠ σ02
の検定を考える.
いま,母集団から大きさ n の無作為標本
x1,x2,…,xn
を抽出したところ,標本平均が x-,標本分散が s2 であったとする.すると,
帰無仮説ももとで(under H0),標本分散に関係した量が,
と自由度 n - 1 の χ2 分布に従うので,U を検定統計量にして検定が行える.
有意水準 5 %の検定は,自由度 n - 1 の χ2 分布の
2.5%点と 97.5%点をそれぞれ χ2(n - 1)0.025,
χ2(n - 1)0.975 とすると,
U < χ2(n - 1)0.025,
U > χ2(n - 1)0.975
のいずれかの不等式を満たしたとき帰無仮説を棄却し,母分散は σ02 と有意に異なる
と結論づける.
2つの母集団分散の同等性の検定
2つの母集団 A,B があり,それぞれが平均を μA,μB,
分散を σA2,σB2 の正規分布に従って
いるが,その値は未知であるとする.このとき,2つの母分散の同等性の検定,
帰無仮説,H0: σA2 =
σB2
対立仮説,H1: σA2 ≠
σB2
の検定を考える.
母集団 A から大きさ nA,母集団 B から大きさ nB の標本を抽出した.
母集団 A からの標本の標本平均が x-A,
標本分散が sA2 であり,母集団 B の
標本平均が x-B,
標本分散が sB2 であるとする.すると,
標本分散に関係した量はそれぞれ
と χ2 分布に従い,それぞれが独立である.これらの量の比は,
のように,自由度 nA - 1,nB - 1 の F 分布に従う.
ところで,帰無仮説が正しいとする
と,σA2 = σB2 とおけるので,
母集団の分散比は,γ0 = σA2/σB2 = 1,
となる.このとき,標本分散の分散比の統計量 γ が,
と,自由度 nA - 1,nB - 1 の F 分布に従うので,この γ 値を検定統計量にして
2つの母分散が等しいという帰無仮説の検定が行える.
すなわち,有意水準 5 %の検定を行うには,自由度 nA - 1,nB - 1 の F 分布
の 2.5%点と 97.5%点をそれぞれ F(nA - 1,nB - 1)0.025,
F(nA - 1,nB - 1)0.975 とすると,検定統計量 γ が,
γ < F(nA - 1,nB - 1)0.025,
γ > F(nA - 1,nB - 1)0.975,
のいずれかの不等式を満たしたとき帰無仮説を棄却し,2つの母集団の分散は有意に異なると結論づける.
2つの母集団の分散比の信頼区間
2つの母集団 A,B の分散 σA2,σB2 の分散比,
γ0 = σA2/σB2,の 95%信頼区間は,
上記の考えから簡単に求めることができる.すなわち,互いに独立に χ2 分布する
変量の比が,標本分散の分散比 γ と母集団分散比 γ0 の比となり,
と分布する.これより,母集団分散比の 95%信頼区間は,
となる.
成功確率(比率)に関する検定
標準正規分布による近似検定(大標本理論)
成功確率 p のベルヌイ試行を n 回行ったときの成功回数 X は,
X 〜 B(n, p),のように2項分布に従う.X の平均と分散はそれぞれ,
E[X ] = np,Var[X ] = np(1 - p),である.
ここで,成功確率が p0 であるという帰無仮説,
H0: p = p0
の検定を考える.帰無仮説のもとでは,成功回数 X は,X 〜 B(n, p0),
と分布するので,X をその平均と標準偏差で標準化すると,中心極限定理から,
のように標準正規分布に漸近的に従う.
これより,近似的な 5%両側検定は,標準正規分布の 97.5%分位点の z0 = 1.96 より
検定統計量 T = |z| の値が大きくなったとき帰無仮説を棄却することで得られる.
なお,二項分布は離散的なので,Yates の連続性の補正(continuity correction)を行った検定統計量を用い,
のとき帰無仮説を棄却する方が近似の精度がよいと言われている.
このように,中心極限定理を利用して,標準正規近似を行って検定を行うやり方を大標本(large sample)理論
といい,コンピュータが発達する以前はもっぱら大標本理論に基づいた検定を行っていた.
比率の正規近似に基づく信頼区間
成功確率 p のベルヌイ試行を n 回行ったとき x 回成功したとすると,成功確率は,
p^ = x/n,と推定される.この推定値は最尤推定値である.
成功回数 x は二項分布し,その平均は E[x ] = np,分散は Var[x ] = np(1 - p),で
あるので,成功確率推定量 p^ の平均は E[p^ ] = E[x/n] = p,
分散は Var[p^ ] = Var[x/n] = Var[x ]/n2 = p(1 - p)/n,
となる.これより,
と漸近的に分布するので,標準正規分布の 97.5%点の z0 = 1.96 を用いると,
近似的に
という不等式が成り立つ.これを整理すると,
という p の2次不等式を解くことに帰着する.いま,p の2次方程式の根を
とすると,この根を用い,p の 95%信頼区間は近似的に
となる.
また,連続性の補正を行うには,成功確率の推定値 p^ を,信頼区間の下限と上限でそれぞれ
というように変えて,信頼区間が少し広くなるようにする.
R では,これらの式を用いて信頼区間を構成しているようである.
ここで,さらに近似を加えて,z02 の項を消去すると,
p の2次方程式の根は,
となるので,p の 近似的な 95%信頼区間は,
と簡略化される.
なお,この信頼区間は,
成功確率推定量 p^ の分散において,真の成功確率 p の
代わりにその推定量 p^ に置き換えて,Var[p^ ]
= p^(1 - p^)/n,とみなした場合と同じで,
この信頼区間は教科書等でよく出てくる.
簡略化された信頼区間で連続性の補正を入れるには,
として,信頼区間の幅を拡げる.
ところで,正規近似による信頼区間の構成では,場合により信頼区間が負になったり 1 を超えることがあるが,
このときは,0 と 1 で切り詰め(truncate)る.
二項確率の計算による正確な検定
現在では二項確率が R などのコンピュータソフトにより直接計算できるので,
正規分布による近似検定を行う意味はあまりないといえる.
いま.独立なベルヌイ試行を n 回行ったところ,成功回数が x であったとする.このとき,
成功確率 p が p0 であるという帰無仮説,とその対立仮説
H0: p = p0,
H1: p ≠ p0
の検定を考える.帰無仮説のもとでは成功回数の期待値は np0 である.
いま,x > np0 であるとする.このときは,まず成功回数
が x 回以上である確率 Pr[X ≧ x] を計算する.これが上側確率で,
である.
両側検定では下側確率を考える必要がある.これは,帰無仮説のもとでデータ x が得られる確率,
より,小さな確率を持つ密度を加え合わせて,
として求められる.これらから,帰無仮説の有意確率(p 値)は,
Pupper + Plower
となり,これが
が 0.05 より小さければ有意水準 5%で帰無仮説を棄却し,0.01 より小さければ有意水準 1%で帰無仮説を棄却
する.
x < np0 のときは,上の上側確率と下側確率の関係が逆になる.
二項確率のベータ分布表現による信頼区間の構成
成功確率 p のベルヌイ試行を n 回行ったときの成功回数の確率変数を X,
パラメータ,x と n - x + 1 のベータ分布に従う確率変数を Y,
Y 〜 beta(x,n - x + 1),とすると,成功回数 X がある回数 x 以上になる確率は,
となる.また,成功回数が x 以下になる確率は,
となる.
これらの関係は,ベータ分布の累積分布を部分積分すると,
となることを利用して求められる.
これより,成功確率 p の 95%信頼区間は,
下限:Beta(x, n - x + 1) 分布の累積確率が 0.025 になる値,qbeta(0.025, x, n - x + 1)
上限:Beta(x + 1, n - x) 分布の累積確率が 0.975 になる値,qbeta(0.975, x + 1, n - x)
として求められる.
ところで,F 分布とベータ分布の関係
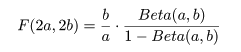
を用いて,成功確率 p の信頼区間を F 分布を用いて構成することもできる.
これは,以前は F 分布の数表が充実していたためであろう.
統計ソフトが発達した現在では,ベータ分布の累積分布関数を用いて信頼区間
を構成するのが普通であり,R でもベータ分布を利用している.
- 成功確率の正確な検定例
成功確率の正確な検定の例として,n = 10 回の試行で x = 7 回の成功が観察されたベルヌイ試行で,
帰無仮説:H0: p = 0.4
対立仮説:H1: p ≠ 0.4
の検定を行ってみる.
まず上側確率を求める.帰無仮説のもとで,x = 7 回の成功が得られる確率を q7 とすると,
これ以上の成功回数 8 回,9 回,10 回が得られる確率,q8,q9,q10,
を加え合わせる.これらは,
となり,上側確率は,
となる.
下側確率は,帰無仮説のもとで,x = 0,1,…,回の成功が得られる確率で q7 より
小さいものを,
q0,q1,…,と求める.これらは,
となり,q2 > q7 なので,求める下側確率は,
となる.
これより p 値は,
Pupper + Plower = 0.05476188 + 0.0463574 = 0.1011193
となる.
# 二項確率の正確な検定の R スクリプト
binom.test(7, 10, p=0.4) # 二項確率に基づく正確な検定
up <- 1 - pbinom(6, 10, prob=0.4); up # 上側確率
pbinom(6, 10, prob=0.4, lower.tail=F) # 上側確率
lp <- pbinom(1, 10, prob=0.4); lp # 下側確率
lp + up # 両側検定 p 値
binom.test(7, 10, p=0.4, alternative="greater") # 片側検定(H1 : p > 0.4)
up # 片側検定 p 値
binom.test(7, 10, p=0.4, alternative="less") # 片側検定(H1 : p < 0.4)
pbinom(7, 10, prob=0.4) # 片側検定 p 値
|
- 二項確率の近似検定と正確な検定の比較
いま,A と B で将棋に強さに違いがあるかを調べるため,10回対戦させたところ,A の 7 勝 3 敗であった.
この結果から A と B で将棋の強さに違いがあると言えるかを考えてみる.A の B に対する勝率を p とすると,
帰無仮説は,A と B で将棋に強さに違いがないなら勝敗は5分5分であろうと考える.また,対立仮説は,
A と B で将棋がどちらが強いか不明なので,両側とする.すなわち,
H0: p = 0.5
H1: p ≠ 0.5
の検定を行う.ところで,比率の検定では,通常,Yates の補正を行った正規近似で検定されてきた.
ここで,正確な検定との比較を行う.
# 二項確率の検定の R スクリプト
|
r <- 7; n <- 10
| # 成功回数と試行回数 |
|
prop.test(r, n, p=0.5, correct=F)
| # H0:p = 0.5 の正規近似検定(補正なし) |
|
prop.test(r, n, p=0.5)
| # H0:p = 0.5 の正規近似検定(連続性の補正) |
|
binom.test(r, n, p=0.5)
| # 二項確率に基づく正確な検定 |
課題:
試行回数を増やして(n = 30)同様な検定を行え.
- テレビ視聴率
テレビ視聴率は,視聴率の高い番組ほど多くの視聴者が見ているので,広告宣伝の効果が高く影響力が
強いと考えられている.このため,視聴率の高さが広告宣伝費用に反映されるので,テレビ会社は高い視聴率を
得ようとして番組を製作している.
ある調査会社のデータによると,関東地区では 600 世帯を対象にしているようである.
課題:ある調査会社によると,NHK 大河ドラマの関東地区世帯視聴率は24.5%であった.
真の世帯視聴率の 95 %信頼区間を求めよ.
8.適合度検定
Pearson χ2 検定
前節の比率の検定は,χ2 分布を用いる適合度検定と大きな関係がある.
ここでは n 回のベルヌイ試行で X 回成功したときに,成功確率が p0 であるという,
帰無仮説,H0: p = p0,
対立仮説,H1: p ≠ p0,
の検定を考えた.そこでは,X を標準化して標準正規分布にもって行ったが,これを2乗して
χ2 分布を用いることもできる.すなわち,
という関係がある.
ところで,n 回のベルヌイ試行の結果と帰無仮説のもとでの期待値を表にすると,
| | 成 功 | 失 敗 |
|---|
| 観測度数 | X | n - X |
|---|
| 期待度数 | np0 | n(1 - p0) |
|---|
となる.ここで,ピアソン(Pearson)のχ2 値,
を計算すると,
となる.つまり,χ2 値は,試行回数 n が大きくなるにつれて
帰無仮説のもとで自由度 1 の χ2 分布に漸近的に従う.よって,これより検定が行える.
- 成功,失敗確率の適合度検定
前節で行った A と B で将棋の強さに違いがあると言えるかの検定を,χ2 値を用いた
ピアソンの適合度検定で行ってみる.適合度検定では,R ではなぜか連続性の補正ができない.
# 適合度検定の R スクリプト
|
r <- 7; n <- 10
| # 成功回数と試行回数 |
|
x <- c(r, n-r)
| # 成功回数と失敗回数のベクトル |
|
p0 <- c(0.5, 0.5)
| # 成功確率と失敗確率の帰無仮説 |
|
chisq.test(x, p=p0)
| # ピアソン χ2 適合度検定 |
確率分布との適合度
確率分布が既知のとき
データが想定している確率分布に適合しているかは,ピアソン(Peason)の χ2 適合度検定で行う
ことができる.いま,離散分布の,たとえば m = 5 のセルに対して,観測されたカウントデータと対応する
想定確率が,
| | セル1 | セル2 | セル3 |
セル4 | セル5 | 計 |
|---|
| 観測度数 | n1 | n2 |
n3 | n4 |
n5 | n |
|---|
| 想定確率分布 | p1 | p2 |
p3 | p4 |
p5 | 1 |
|---|
のようになっていたとする.このとき,ピアソン(Peason)の χ2 値は,
のように近似的に自由度 m - 1 の χ2 分布に従う.これにより,データが想定確率分布に
適合しているかの検定が行える.検定の帰無仮説は,
H0:データは想定確率分布に従う.
である.
この近似は n が大きく,各セルの度数 ni が 5 以上である
ことが望ましい,とされている.
一方,正規分布などの連続分布では,適当に階級分けして離散化すればこの検定が行える.ただし,階級分け
は任意なので,階級分けのやり方によっては結果が異なる恐れがある.
- 過去の分布との比較
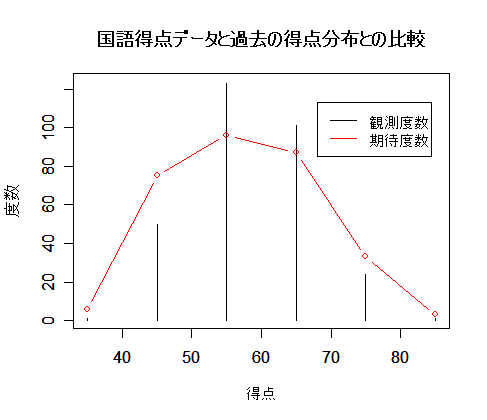
以下の表のある学校での国語テストの得点分布が,過去の得点分布と同じであるかを調べたい.
セルの数が 6 なので,
ピアソンの χ2 適合度検定で自由度を 5 にすればよい.
| 得 点 | 30〜39 | 40〜49 | 50〜59 | 60〜69 |
70〜79 | 80〜89 |
|---|
| 人 数 | 1 | 50 |
123 | 101 |
24 | 1 |
|---|
| 過去の確率分布 | 0.02 | 0.25 |
0.32 | 0.29 |
0.11 | 0.01 |
|---|
# 国語得点分布適合度検定の R スクリプト
|
x <- c(35, 45, 55, 65, 75, 85)
| # 階級の代表値 |
|
y <- c(1, 50, 123, 101, 24, 1)
| # 観測度数 |
|
p0 <- c(0.02, 0.25, 0.32, 0.29, 0.11, 0.01)
| # 過去の確率分布 |
|
chisq.test(y, p=p0)
| # χ2 適合度検定 |
|
s <- sum(y)
| # |
|
plot(x, y, type="h", xlab="得点", ylab="度数")
| # 観測度数のグラフ |
|
points(x, s*p0, type="b", col="red")
| # 期待度数のグラフ |
|
legend(68,113, c("観測度数", "期待度数"), lty=1, col=c("black","red"))
|
|
title(main="国語得点データと過去の得点分布との比較")
| # |
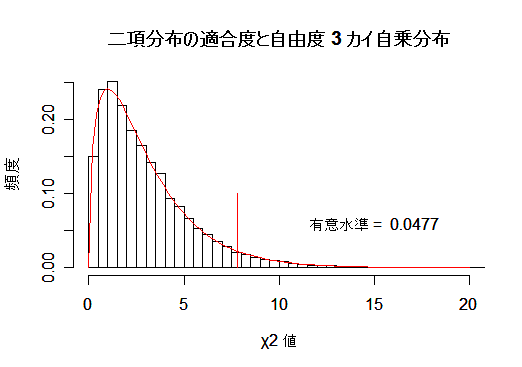
- 二項分布
二項分布の場合にピアソン(Peason)の χ2 値がどの程度 χ2 分布
で近似されるかをみてみる.成功確率 p = 1/3 の試行を m = 6 回行ったときの成功回数 x の分布は
二項分布 B(6, 1/3) に従う.これを n = 100 回行ったとすると,期待度数は,
| 成功回数 | 0 回 | 1 回 |
2 回 | 3 回 |
4 回 | 5 回 |
6 回 |
計 |
|---|
| 期待観測度数 | 8.8 | 26.3 |
32.9 | 22.0 | 8.2 |
1.7 | 0.1 | 100 |
|---|
となり,成功回数 5 回と 6 回は期待度数が小さいのでこれらをまとめ,成功回数 4 回以上
とする.すると,成功回数のセル数は 5 となる.
n = 100 回を 1 回行うと観測度数が得られるので,χ2 値が計算される.これを,
N = 10000 回行うと,帰無仮説が正しいときの χ2 値の分布がシミュレートされる.
χ2 値のヒストグラムを自由度 5 - 1 = 4 の χ2 分布と比べればよい.
また,自由度 4 の χ2 分布の 95% 分位点の値と比較して名目上の第1種の過誤が達成されている
かをみる.
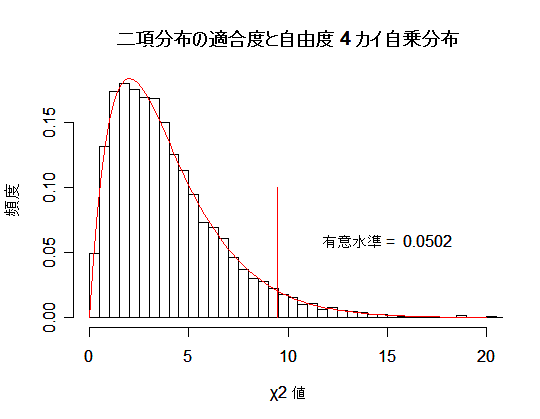
# 二項分布適合度検定シミュレーションの R スクリプト
|
N <- 10000 | # シミュレーション回数 |
|
m <- 6 | # 試行1回でのベルヌイ試行の数 |
|
n <- 100 | # 二項確率の試行数 |
|
p0 <- dbinom(x=0:6, size=6, p=1/3) | # 二項確率 B(6, 1/3) |
|
w <- rbinom(n, m, p=1/3) | # n = 100 回の試行での成功回数(観測値)の系列) |
|
tw <- table(factor(w,levels=0:m)) | # 成功回数の表(データ) |
|
r <- chisq.test(tw, p=p0) | # データと二項確率との適合度検定 |
|
p1 <- c(p0[1:4], p0[5]+p0[6]+p0[7]) | # 少ない確率をまとめた二項確率 |
|
y <- NULL | # χ2 値のベクトル |
|
for(i in 1:N){ | # |
|
w <- rbinom(n, m, p=1/3) | # n = 100 回の試行での成功回数(観測値)の系列) |
|
fw <- table(factor(w,levels=0:m)) | # 成功回数の表(データ) |
|
tw <- c(fw[1:4], fw[5]+fw[6]+fw[7]) | # 成功回数 5,6,7 をまとめる |
|
r <- chisq.test(tw, p=p1) | # 適合度検定の χ2 値 |
|
y <- c(y, r$statistic) | # |
|
} | # |
|
my <- ceiling(max(y)) | # y の最大値を超える最小の整数 |
|
mean(y) | # 平均(真値 = 4) |
|
var(y) | # 分散(真値 = 8) |
|
hist(y, breaks=seq(0,my,by=0.5),freq=FALSE,xlim=c(0,20),xlab="χ2 値",ylab="頻度",main="")
|
|
x <- seq(0,20, by=0.1) | # |
|
curve(dchisq(x, 4), 0, 20, add=T, col=2) | # 自由度 4 χ2 分布 |
|
title(main="二項分布の適合度と自由度 4 カイ自乗分布") | # |
|
q0 <- qchisq(0.95,df=4) | # χ2(4) の 95%点 |
|
segments(q0,0, q0,0.1, col="red") | # 棄却域 |
|
pv <- length(y[y>q0])/N | # |
|
s <- paste("有意水準 = ", pv) | # 帰無仮説の棄却率(真値 = 0.05) |
|
text(15,0.06, s) | # |
確率分布のパラメータをデータから推定する場合
確率分布のタイプ(二項分布やポアソン分布など)は想定できるが,パラメーターはデータから推定することが
普通であろう.このときは,推定されたパラメーターのもとでの推定確率分布を用いて,セル数が m = 5 のときは,
| | セル1 | セル2 | セル3 |
セル4 | セル5 | 計 |
|---|
| 観測度数 | n1 | n2 |
n3 | n4 |
n5 | n |
|---|
| 推定確率分布 |
p^1 |
p^2 |
p^3 |
p^4 |
p^5 |
1 |
|---|
のような表ができる.推定したパラメーターの数が k であったとすると,
このとき,ピアソン(Peason)の χ2 値は,
のように近似的に自由度 m - k - 1 の χ2 分布に従う.これにより,データが推定確率分布に
適合しているかの検定が行える.
- 二項分布
成功確率を推定する二項分布の場合にピアソン(Peason)の χ2 値がどの程度 χ2 分布
で近似されるかをみてみる.成功確率 p = 1/3 の試行を m = 6 回行ったときの成功回数 x の分布は
二項分布 B(6, 1/3) に従う.これを n = 100 回行ったとすると,たとえば,
| 成功回数 | 0 回 | 1 回 |
2 回 | 3 回 |
4 回 | 5 回 |
6 回 |
計 |
|---|
| 観測度数 | 12 | 18 |
25 | 32 | 13 |
0 | 0 | 100 |
|---|
のようなデータがえられる.このときの成功確率の推定値は,
p^ = Σ xi / (mn) = 0.36,となる.この推定確率から二項分布
の確率分布を出し,χ2 値を計算する.この場合,成功確率をデータに合わせているので,
先ほどの p = 1/3 よりは χ2 値は小さくなるはずである.このため,χ2 分布
の自由度を小さくする必要がある.
成功回数 5 回と 6 回は観測度数が小さいのでこれらをまとめ,成功回数 4 回以上
とする.すると,成功回数のセル数は 5 となる.また,推定パラメーター数は 1 である.
n = 100 回を 1 回行うと観測度数が得られるので,χ2 値が計算される.これを,
N = 10000 回行うと,帰無仮説が正しいときの χ2 値の分布がシミュレートされる.
χ2 値のヒストグラムを自由度 5 - 2 = 3 の χ2 分布と比べればよい.
また,自由度 3 の χ2 分布の 95% 分位点の値と比較して名目上の第1種の過誤が達成されている
かをみる.
# 二項分布適合度検定シミュレーションの R スクリプト
|
N <- 10000 | # シミュレーション回数 |
|
m <- 6 | # 試行1回でのベルヌイ試行の数 |
|
n <- 100 | # 二項確率の試行数 |
|
y <- NULL | # χ2 値のベクトル |
|
for(i in 1:N){ | # |
|
w <- rbinom(n, m, p=1/3) | # n = 100 回の試行での成功回数(観測値)の系列) |
|
pd <- mean(w)/m | # データのもとでの推定成功確率 |
|
p0 <- dbinom(x=0:6, size=6, p=pd) | # 推定成功確率のもとでの二項確率分布 |
|
p1 <- c(p0[1:4], p0[5]+p0[6]+p0[7]) | # 少ない確率をまとめた二項確率 |
|
fw <- table(factor(w,levels=0:m)) | # 成功回数の表(データ) |
|
tw <- c(fw[1:4], fw[5]+fw[6]+fw[7]) | # 成功回数 5,6,7 をまとめる |
|
r <- chisq.test(tw, p=p1) | # 適合度検定の χ2 値 |
|
y <- c(y, r$statistic) | # |
|
} | # |
|
my <- ceiling(max(y)) | # y の最大値を超える最小の整数 |
|
mean(y) | # 平均(真値 = 4) |
|
var(y) | # 分散(真値 = 8) |
|
hist(y, breaks=seq(0,my,by=0.5),freq=FALSE,xlim=c(0,20),xlab="χ2 値",ylab="頻度",main="")
|
|
x <- seq(0,20, by=0.1) | # |
|
curve(dchisq(x, 3), 0, 20, add=T, col=2) | # 自由度 3 χ2 分布 |
|
title(main="二項分布の適合度と自由度 3 カイ自乗分布") | # |
|
q0 <- qchisq(0.95,df=3) | # χ2(3) の 95%点 |
|
segments(q0,0, q0,0.1, col="red") | # 棄却域 |
|
pv <- length(y[y>q0])/N | # |
|
s <- paste("有意水準 = ", pv) | # 帰無仮説の棄却率(真値 = 0.05) |
|
text(15,0.06, s) | # |
- Weldon のサイコロ実験の適合度検定
前期であつかった Weldon のサイコロ実験の適合度検定を行ってみる.
12個のサイコロを同時に投げ,5か6の目が出た個数をカウントした.
| 5,6の個数 |
0 | 1 |
2 | 3 |
4 | 5 |
| 出た回数 |
185 |
1149 |
3265 |
5475 |
6114 |
5194 |
| 5,6の個数 |
6 |
7 |
8 | 9 |
10 以上 | 合計 |
| 出た回数 |
3067 |
1331 |
403 |
105 |
18 |
26306 |
# サイコロ実験適合度検定の R スクリプト
|
x <- 0:10 | # 5,6の個数 |
|
y <- c(185,1149,3265,5475,6114,5194,3067,1331,403,105,18) | # 出た回数 |
|
m <- sum(x*y)/sum(y) | # 出た回数の平均 |
|
pd <- m/12 | # 5,6 の出る確率の推定値 |
|
p <- dbinom(x=0:12, size=12, p=1/3) | # 正しいサイコロ(p = 1/3)のときの確率分布 |
|
p0 <- c(p[1:10], p[11]+p[12]+p[13]) | # 出る回数 10 回以上をまとめた確率分布 |
|
rbind(y, p0*sum(y)) | # 観測度数とモデルのもとでの期待度数 |
|
chisq.test(y, p=p0) | # データが p = 1/3 の二項分布に従っていることの検定 |
|
q <- dbinom(x=0:12, size=12, p=pd) | # データから推定された確率に基づく二項分布 |
|
q0 <- c(q[1:10], q[11]+q[12]+q[13]) | # 出る回数 10 回以上にまとめた確率分布 |
|
rbind(y, q0*sum(y)) | # 観測度数とモデルのもとでの期待度数 |
|
r <- chisq.test(y, p=q0) | # データが p = pd の二項分布に従っていることの検定 |
|
pchisq(r$statistic, df=r$parameter-1, lower.tail=F) | # 有意確率(自由度1落とす) |
- 12人の兄弟中の女児数のデータ
19世紀末のドイツの病院のデータによると,同じ両親で12人きょうだいがいる6155家族の女児数
の数は以下のようであった.
| 女児数 |
0 | 1 |
2 | 3 |
4 | 5 |
6 |
| 度数 |
7 |
45 |
181 |
478 |
829 |
1112 |
1343 |
| 女児数 |
7 |
8 | 9 |
10 | 11 |
12 | 合計 |
| 度数 |
1033 |
670 |
286 |
104 |
24 |
3 | 6155 |
課題:「Weldon のサイコロ実験」と同様に「12人の兄弟中の女児数のデータ」に対して
二項分布に対する適合度検定を行え.
他の分布
ポアソン分布や負の二項分布などの離散分布では,前節の二項分布のときと同様に適合度検定が行える.
正規分布などの連続型分布では,多少恣意的にはなるが離散化を行えば適合度検定が行える.
- 虫歯数データの負の二項分布との適合度検定
虫歯数データに対し,負の二項分布をモーメント法でパラメータ推定をしたところ,
n^0 = 11.3315,p^0 = 0.7729,が得られ,
最尤法による
パラメーター推定値として,n^ = 8.005,
p^ = 0.7037,が得られた.これらの推定値をパラメーターとする負の二項分布の確率密度
にデータ数をかけたものを期待度数とし,自由度をパラメーター分の 2 つ減らした χ2 適合度検定を行い,
どちらの推定値がよく適合
しているかを比較する.
小学生1人あたりの虫歯数
| 虫歯の数 |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8以上 |
| 児童の数 |
4 | 9 |
16 | 13 |
9 | 7 |
5 | 4 |
3 |
# 虫歯の数モーメント法推定の適合度検定の R スクリプト
|
y <- c(4,9,16,13,9,7,5,4,3)
| # 児童数 |
|
n <- 11.3315
| # モーメント法による n の推定値 |
|
p <- 0.7729
| # モーメント法による p の推定値 |
|
r <- length(y)-2
| # |
|
q <- dnbinom(0:r, size=n, prob=p)
| # 虫歯数 0 から 7 までの確率 |
|
q[r+2] <- pnbinom(r, size=n, prob=p, lower.tail=F)
| # 虫歯数 8 以上の確率 |
|
rbind(y, q*sum(y))
| # 観測値と期待度数 |
|
r <- chisq.test(y, p=q)
| # χ2 適合度検定 |
|
pchisq(r$statistic, df=r$parameter-2, lower.tail=F)
| # 有意確率(自由度 2 落とす) |
課題: 虫歯の数データに,負の二項分布のパラメーターの最尤推定値をあてはめたときの適合度
検定を行い,モーメント法との比較を行え.
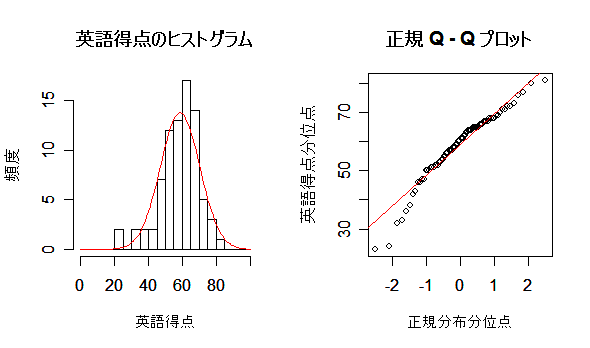
- 英語得点データの正規分布との適合度検定
英語得点データの標本平均と標本分散を,正規分布の平均と分散とみなして正規分布をあてはめた.
Q - Q プロットでみると,下の方の得点分布とあてはまりが悪いようにみえる.
χ2 適合度検定を行うため,40 点以下と 41 点から 50 点,70 点以上をそれぞれ1つの階級とし,
51 点から 70 点までは 5 点きざみの階級にして,全部で 7 セルに離散化した.
すると,以下の表のようにまとめられた.これに合わせて,正規分布を 7 区間に区切り,各区間ごとの確率を
累積分布関数を用いて計算すれば,期待度数を求めることができる.χ2 適合度検定では,
自由度をパラメーター分(平均,分散)の 2 つ減らす.
英語得点データ
| 得点 |
40 未満 |
41 〜 50 |
51 〜 55 |
56 〜 60 |
61 〜 65 |
66 〜 70 |
70 以上 |
| 人数 |
6 |
9 |
12 |
13 |
17 |
14 |
9 |
| 期待度数 |
4.33 |
13.95 |
11.91 |
13.60 |
12.93 |
10.24 |
13.06 |
しかしながら,英語得点データのように正規分布などの連続分布をデータにあてはめた場合の
あてはまりの良さを調べる場合,χ2 適合度検定は,離散化に恣意性が入るのであまり
薦められない.連続型データの場合は,次に述べる Kolmogorov-Smirnov 検定を用いるのが普通である.
- 英語得点データの正規分布との Kolmogorov-Smirnov 検定
累積分布関数 F(・) を持つと想定される母集団から,大きさ n の
無作為標本,X1,…,Xn,が抽出されたとする.このとき,
を経験(標本)累積分布関数という.この経験累積分布関数と母集団の累積分布関数との
最大偏差,
を検定統計量とする.
標本が累積分布関数 F(・) を持つ母集団から抽出されたならば,最大偏差 D は
それ程大きくないと考えられる.帰無仮説,
H0:標本は分布 F(・) から由来した
を最大偏差 D を用いて検定する方法を,Kolmogorov-Smirnov 1標本検定
と言う.Kolmogorov-Smirnov 検定には,2つの経験累積分布関数が同じ分布から由来したかを
検定する Kolmogorov-Smirnov 2標本検定もある.
# 英語得点の正規分布適合度検定の R スクリプト
|
eigo <- c(
36,70,56,68,76,60,50,63,62,42,64,60,50,68,71,67,
| # 英語得点データ |
|
50,65,67,57,72,64,61,66,46,80,46,51,59,32,55,65,
65,52,57,64,23,57,53,54,38,71,57,69,77,61,51,64,
|
|
63,43,65,61,51,69,72,68,53,66,68,58,73,65,62,67,
47,81,47,52,59,33,56,66,67,52,58,65,24,58,54,55)
|
|
d <- 5
| # ヒストグラムの階級幅 |
|
op <- par(mfrow = c(1, 2))
| # グラフを横に2つ並べて表示 |
|
hist(eigo, breaks=seq(0, 100, by=d), xlab="英語得点", ylab="頻度", main="")
|
|
n <- length(eigo)
| # データ数 |
|
m <- mean(eigo)
| # 平均 |
|
s <- sd(eigo)
| # 標準偏差 |
|
x <- 0:100
| # |
|
curve(n*d*dnorm(x, m, s), 0, 100, add=TRUE, col="red")
| # 推定正規分布重ねて表示 |
|
title(main="英語得点のヒストグラム")
| # |
|
qqnorm(eigo, xlab="正規分布分位点", ylab="英語得点分位点", main="")
|
|
qqline(eigo, col=2)
| # Q-Q プロット |
|
title(main="正規 Q - Q プロット")
| # |
|
par(op)
| # |
|
a <- c(0,40,50,55,60,65,70,100)
| # 階級の区切り点の定義 |
|
b <- hist(eigo, breaks=a)
| # 各セルに入る人数の計算 |
|
y <- b$counts
| # セルの観測度数 |
|
l <- length(a)
| # |
|
p <- pnorm(a[2:(l-1)], mean=m, sd=s)
| # 階級の区切りまでの累積確率 |
|
ps <- c(0, p)
| # |
|
pe <- c(p, 1)
| # |
|
q <- pe-ps
| # セルの確率分布 |
|
rbind(y, sum(y)*q)
| # セルの観測度数と期待度数 |
|
r <- chisq.test(y, p=q)
| # χ2 適合度検定 |
|
pchisq(r$statistic, df=r$parameter-2, lower.tail=F)
| # 有意確率(自由度 2 落とす) |
|
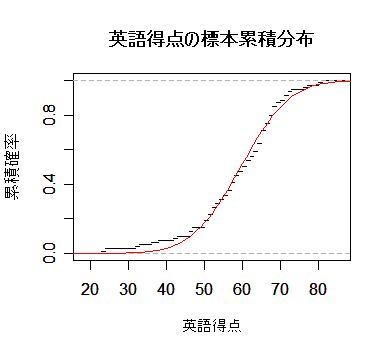
plot(ecdf(eigo), xlab="英語得点", do.points=F, ylab="累積確率", main="")
|
|
curve(pnorm(x, m, s), 0, 100, add=TRUE, col="red")
| # 正規分布の累積分布 |
|
title(main="英語得点の標本累積分布")
| # |
|
ks.test(eigo, "pnorm", m, s)
| # Kolmogorov-Smirnov 1標本検定 |
課題: 英語得点データでは 25 点以下の 2 名が他の集団から離れているようにみえる.
この 2 名を異常値(out-lier)としてデータから除き,正規分布との適合度検定を行い,
あてはまりがどう変化したかを考察せよ.
参考文献(古い順)
- Introduction to the Theory of Statistics, Mood, A. M., Graubill, F. A. & Boes, D. C., 1974,
McGRAW-HILL
- 工学のためのデータサイエンス入門−フリーな統計環境Rを用いたデータ解析−,間瀬茂ら,2004,
数理工学社
- 実践生物統計学−分子から生態まで−(第 1 章,第 2 章),
東京大学生物測定学研究室編(大森宏ら),
2004,朝倉書店
- The R Tips データ解析環境 R の基本技・グラフィックス活用集,船尾暢男,2005,九天社
- R で学ぶデータマインニング I −データ解析の視点から−,熊谷悦生・船尾暢男,2007,九天社
- R で学ぶデータマインニング II −シミュレーションの視点から−,熊谷悦生・船尾暢男,2007,九天社
Copyright (C) 2008, Hiroshi Omori. 最終更新日:2008年 7月13日