
# MeCab の実行確認 library(RMeCab) txt <- "「田舎の祖父母の家」のような懐かしさが感じられた。" res <- RMeCabC(txt) unlist(res)
####### Start of function #############
mkmat <- function(wg){ # 0 - 1 行列を作成する関数の定義
n <- length(wg) # ベクトルの長さ(画像数)
maxg <- max(wg) # グループ最大値
ming <- min(wg) # グループ最小値(普通は1)
if(!ming){ # 最小値が 0 のときの処置
ming <- 1; maxg <- maxg+1; wg <- wg+1 # グループ数を 1 つ増やす
} #
gmat <- matrix(0, nrow=n, ncol=maxg) # n × maxg 行列(値は 0)
for(i in ming:maxg){ # グループごとの処理
ng <- (1:n)[wg == i] # グループ i に所属する行番号(画像番号)
gmat[ng, i] <- 1 # 上の行番号と i 列の値を 1 にする
} #
return(gmat) #
} #
######## End of function ##############
# グルーピングデータの読み込み
pg <- read.csv("pansygr.csv", header=TRUE, row.names=1); pg
n <- ncol(pg) # パンジーの数
S <- matrix(0, nrow=n, ncol=n) # 類似度行列の定義
for(i in 1:nrow(pg)){ #
w <- mkmat(pg[i, ]) # 学生ごとのグルーピング行列
S <- S + w %*% t(w) # 学生ごとの類似度行列を加える
}
rownames(S) <- colnames(S) <- colnames(pg)
D <- max(S) - S # 非類似度行列への変換
####
tcmd <- cmdscale(D, k=4, eig=TRUE, add=TRUE) # 多次元尺度法(MDS)
tcmd$eig[1:5] # MDS の固有値
panmds <- tcmd$points # MDS の座標を panmads に格納
colnames(panmds) <- paste("MDS", 1:4, sep="")
plot(panmds[,1:2], type="n") # 1軸と2軸
text(panmds[,1:2], rownames(panmds), cex=0.8)
title(main="MDS of pansy flowers")
#
pclus <- hclust(as.dist(D), method="ward.D")
#pclus <- hclust(dist(D))
plot(pclus, cex=0.6, main="パンジーの類似度によるクラスター")
#
# 好きなパンジー、嫌いなパンジー
likeall <- read.csv("likeall.csv", header=T, row.names=1)
dim(likeall)
n <- ncol(likeall); m <- nrow(likeall)
like.no <- matrix(0, nrow=m, ncol=n)
dislike.no <- matrix(0, nrow=m, ncol=n)
colnames(like.no) <- colnames(dislike.no) <- colnames(likeall)
rownames(like.no) <- rownames(likeall)
rownames(dislike.no) <- paste(rownames(likeall), "d", sep="")
for(i in 1:m){
v1 <- which(likeall[i,]==1)
like.no[i,v1] <- 1
v2 <- which(likeall[i,]==2)
dislike.no[i,v2] <- 1
}
stl <- which(apply(like.no,1,sum) > 0)
std <- which(apply(dislike.no,1,sum) > 0)
length(stl) # 213
length(std) # 207
length(which(stl %in% std)) # 207
#
like.no <- like.no[std,]
dislike.no <- dislike.no[std,]
m <- nrow(like.no)
#
# 好まれたパンジー
like.pansy <- apply(like.no, 2, sum)
opl <- order(like.pansy, decreasing=T)
like.pansy[opl[1:10]]
# 同様にして好まれていないパンジーもわかる
dislike.pansy <- apply(dislike.no, 2, sum)
#
barplot(like.pansy, col="red")
barplot(rbind(like.pansy, dislike.pansy), width=0.2,beside=T, col=c("red","blue"))
ld.pansy <- like.pansy-dislike.pansy
barplot(ld.pansy)
res <- lm(ld.pansy ~ panmds[,1:4])
summary(res)
#
#
likeall <- rbind(like.no, dislike.no)
pno <- which(apply(likeall,2,sum) > 0)
library(MASS)
stres <- corresp(likeall[,pno], nf=4)
stres$cor
#
biplot(stres, cex=0.7)
com <- c(1,4)
#obj <- stres$rscore[,com]
obj <- stres$cscore[,com]
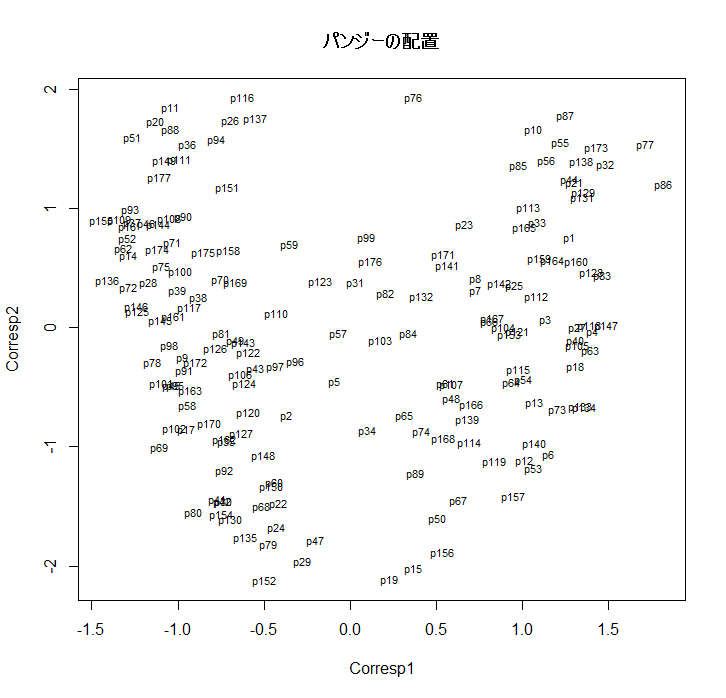
plot(obj, type="n", xlab="Corresp1", ylab="Corresp2")
text(obj, rownames(obj), cex=0.7)
title(main="パンジーの配置")
#
plot(stres$rscore[,com], type="n", xlab="Corresp1", ylab="Corresp2")
l1 <- stres$rscore[1:m,com[1]]
l2 <- stres$rscore[1:m,com[2]]
d1 <- stres$rscore[(m+1):(2*m),com[1]]
d2 <- stres$rscore[(m+1):(2*m),com[2]]
arrows(d1, d2, l1, l2, col="lightgreen", length=0.15)
text(stres$rscore[(m+1):(2*m),com], rownames(stres$rscore)[(m+1):(2*m)], col="blue", cex=0.8)
text(stres$rscore[1:m,com], rownames(stres$rscore)[1:m], col="red", cex=0.8)
legend(-1.7,-2, legend=c("好き","嫌い"), pch=c("l","d"), col=c("red","blue"))
title(main="人の嫌い―>好きベクトル")
#
#
# 対応分析の好き座標と嫌い座標から人の間の距離を計算
like.cp <- stres$rscore[1:m,1:2]
dislike.cp <- stres$rscore[(m+1):(2*m),1:2]
like.dist <- dist(like.cp)
dislike.dist <- dist(dislike.cp)
cp.dist <- like.dist + dislike.dist
#sclus <- hclust(cp.dist)
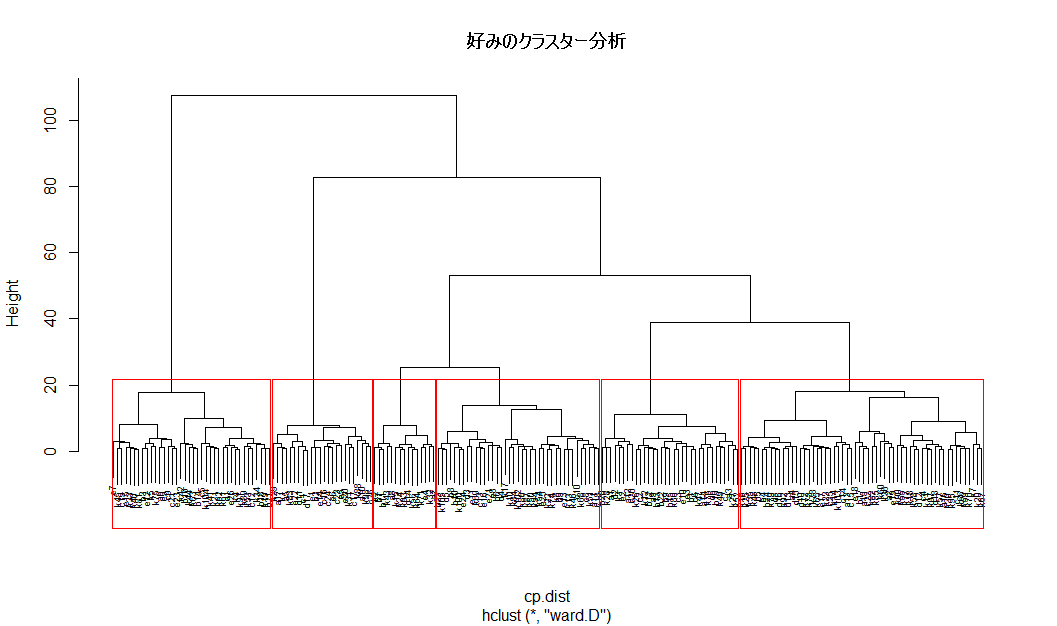
sclus <- hclust(cp.dist, method="ward.D")
plot(sclus, cex=0.6, main="好みのクラスター分析")
sclass <- rect.hclust(sclus, h=20)
sgroup <- rep(0, nrow(like.no))
for(i in 1:length(sclass))
sgroup[sclass[[i]]] <- i
#
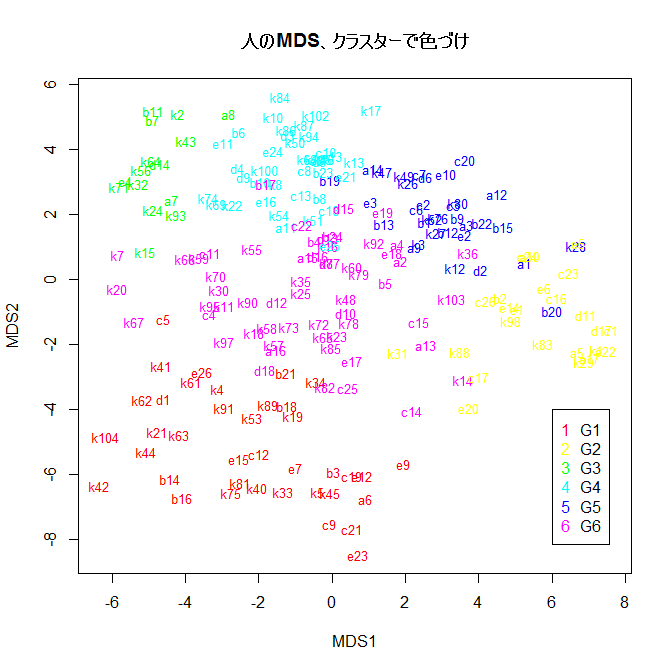
stcmd <- cmdscale(cp.dist, k=4, eig=TRUE, add=TRUE)
stcmd$eig[1:5] # MDS の固有値
stmds <- stcmd$points # MDS の座標を panmads に格納
colnames(stmds) <- paste("MDS", 1:4, sep="")
plot(stmds[,1:2], type="n") # 1軸と2軸
text(stmds[,1:2], rownames(stmds), col=rainbow(length(sclass))[sgroup], cex=0.8)
legend(6,-4, legend=paste("G",1:length(sclass),sep=""), pch=as.character(1:length(sclass)), col=rainbow(length(sclass)))
title(main="人のMDS、クラスターで色づけ")
#
パンジーの類似度から上のクラスター分析(ward 法)により並べ替えたもの。左の数字は、好きの人数。 右の数字は嫌いの人数。
人の好みの対応分析
 |
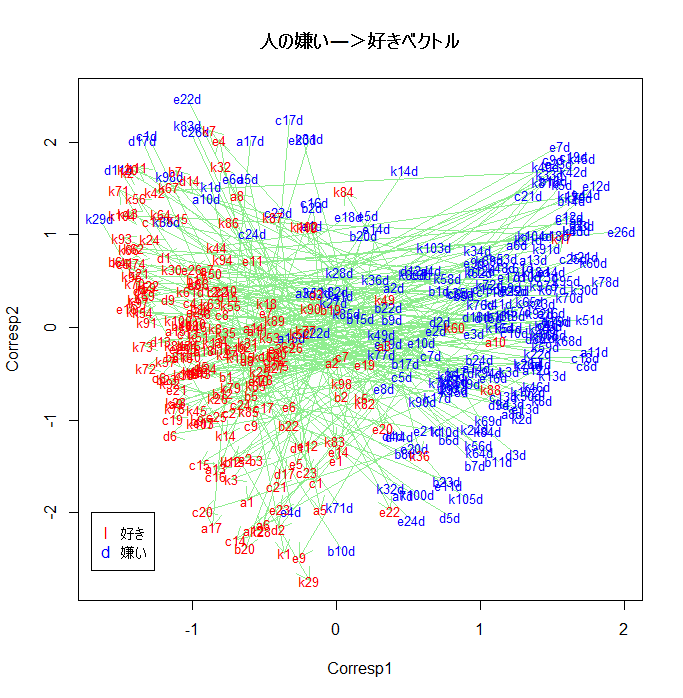 |
人の好みのクラスター
pansy <- read.csv("commentall.csv", header=T, row.names=1)
library(RMeCab)
meishi <- docMatrixDF(pansy[,"like"], pos="名詞")
keiyo <- docMatrixDF(pansy[,"like"], pos="形容詞")
doshi <- docMatrixDF(pansy[,"like"], pos="動詞")
like <- rbind(meishi, keiyo, doshi)
colnames(like) <- rownames(pansy)
rownames(like)
dim(like)
#
meishi <- docMatrixDF(pansy[,"dislike"], pos="名詞")
keiyo <- docMatrixDF(pansy[,"dislike"], pos="形容詞")
doshi <- docMatrixDF(pansy[,"dislike"], pos="動詞")
dislike <- rbind(meishi, keiyo, doshi)
colnames(dislike) <- rownames(pansy)
rownames(dislike)
dim(dislike)
#
#write.csv(like, file="like.csv")
#write.csv(dislike, file="dislike.csv")
# MeCab インストール失敗した人
like <- read.csv("like.csv", row.names=1, header=T)
dislike <- read.csv("dislike.csv", row.names=1, header=T)
# 同義語をまとめる
dogi <- vector("list",17)
dogi[[1]] <- c("紫","紫色")
dogi[[2]] <- c("青", "青色")
dogi[[3]] <- c("きれい","キレイ","綺麗")
dogi[[4]] <- c("さわやか","さわやかさ")
dogi[[5]] <- c("組合せ", "組み合わせ")
dogi[[6]] <- c("グラデーション", "グラーデーション", "グラデ")
dogi[[7]] <- c("赤", "レッド")
dogi[[8]] <- c("花", "はな")
dogi[[9]] <- c("花びら", "花弁")
dogi[[10]] <- c("好き", "すき")
dogi[[11]] <- c("良い", "よい", "いい")
dogi[[12]] <- c("かわいい", "可愛らしい")
dogi[[13]] <- c("落ち着く", "落ちつく")
dogi[[14]] <- c("不揃い", "不ぞろい")
dogi[[15]] <- c("黒", "黒色")
dogi[[16]] <- c("黄", "黄色")
dogi[[17]] <- c("汚い", "汚らしい")
#
####### Start of function ############
delsynonym <- function(text0){
text1 <- text0
drop <- NULL
for(j in 1:length(dogi)){
m1 <- which(rownames(text0)==dogi[[j]][1])
if(length(m1)>0){
m2 <- numeric(0)
for(k in 2:length(dogi[[j]])){
w <- which(rownames(text0)==dogi[[j]][k])
if(length(w)>0){
m2 <- c(m2, w)
text1[m1,] <- text1[m1,]+text0[m2[k-1],]
}
}
}
if(length(m2)>0)
drop <- c(drop,m2)
}
text1[-drop,]
}
######## End of function ##############
like <- delsynonym(like)
dislike <- delsynonym(dislike)
#
# ストップワードの設定
stopwords <- c(
"いる", "もの", ",", "する", "思う", "的", "よう", "番", "ある", "の", "なる",
"さ", "ため", "ない", "られる", "これら", "・", "方", "しまう","れる",".","そう",
"私","自分"
)
#
# ストップワード削除
sw <- which(rownames(like) %in% stopwords)
like <- like[-sw,]
sw <- which(rownames(dislike) %in% stopwords)
dislike <- dislike[-sw,]
dim(like); dim(dislike)
#
# 頻出単語抽出
like.word <- apply(like,1,sum)
ol <- order(like.word, decreasing=T)
like.word[ol[1:50]]
dislike.word <- apply(dislike,1,sum)
od <- order(dislike.word, decreasing=T)
dislike.word[od[1:50]]
#