統計解析ソフトRを用いて,統計解析の理論と実践を学ぶ
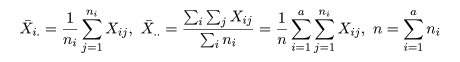
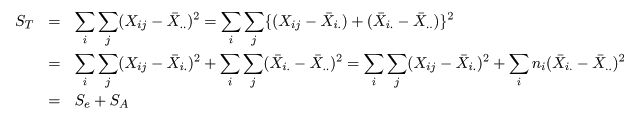
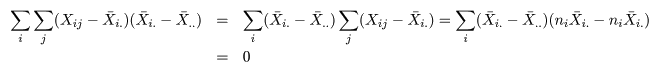
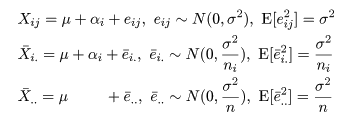
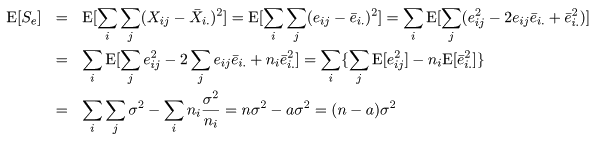
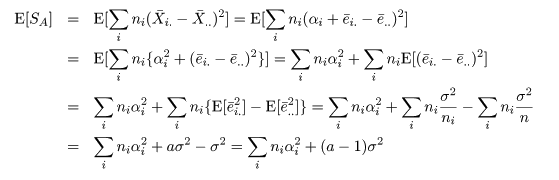
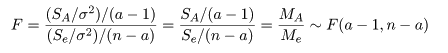
| 変動因 | 自由度(df) | 平方和(S.S.) | 平均平方(M.S.) | F 値 |
|---|---|---|---|---|
| 主効果 | a - 1 | SA | MA = SA/(a - 1) | MA/Me |
| 誤 差 | n - a | Se | Me = Se/(n - a) | |
| 全 体 | n - 1 | ST |
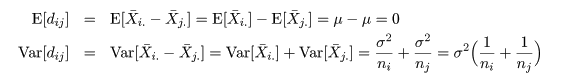
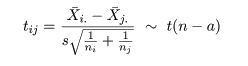
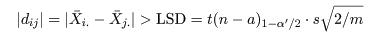
a <- 5; n <- 10 # 処理水準数 a,処理内標本数 n x <- NULL # for(i in 1:a) x <- c(x, rep(i, n)) # グループラベル x <- factor(x) # ラベル化 y <- rnorm(n*a) cbind(y, x) av <- aov(y ~ x) # 分散分析 summary(av) pairwise.t.test(y, x) # 対比較ホルム補正 pairwise.t.test(y, x, p.adj = "bonf") # 対比較ボンフェローニ補正 pairwise.t.test(y, x, p.adj = "none") # 対比較補正なし TukeyHSD(av) # チューキー HSD |
pairwise.t.test(y, x, p.adj = "none") # 対比較補正なし
だと,本来差が無いはずなのに,差があるとしてしまいゴーストを拾ってしまう.従って,
多くの比較を行う場合,補正しないといけない.
hinsyu <- read.csv("hinsyu.csv"); hinsyu # csv データ読み込み
n <- nrow(hinsyu)
m <- ncol(hinsyu)
boxplot(hinsyu)
idname <- rep(names(hinsyu), each=n)
hinsyu.vec <- as.vector(as.matrix(hinsyu))
hinsyu.fr <- data.frame(data = hinsyu.vec, id = idname)
table(hinsyu.fr$id)
av <- aov(hinsyu.fr$data ~ hinsyu.fr$id) # 分散分析
summary(av)
|
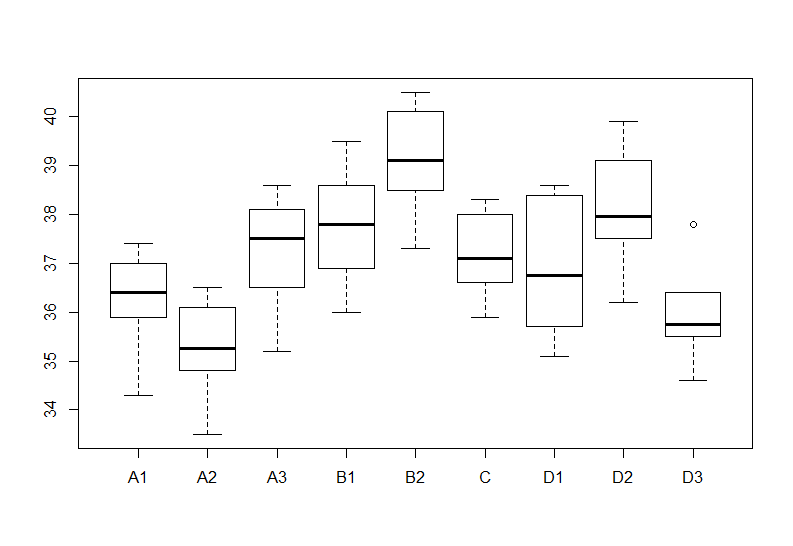
pis <- read.csv("pistachioSize.csv")
attach(pis) # pisデータの使用を宣言
seven <- which(store=="seven") # seven ブランドのみデータを取得
boxplot(size[seven] ~ group[seven])
res <- lm(size[seven] ~ group[seven])
summary(res)
anova(res)
#
boxplot(size ~ store)
res <- lm(size ~ store)
summary(res)
anova(res)
detach(pis) # pisデータ使用終了
|
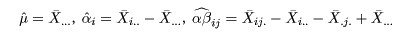
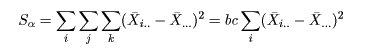
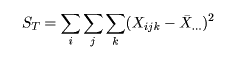
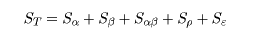
|
|||||||||||||||||||||||||||||||||||||
| * : 5 % 有意 |
rice <- read.csv("ricecul.csv") # データ読み込み
rice
yield <- rice$gy
dense <- factor(rice$density) # 水準のラベル化
fert <- factor(rice$fert)
blk <- factor(rice$rep)
tapply(yield[1:12], dense[1:12], mean) # 密度水準ごとの平均
tapply(yield[1:12], fert[1:12], mean)
tapply(yield[1:12], blk[1:12], mean)
cm <- tapply(yield[1:12], dense[1:12]:fert[1:12], mean); cm # 処理組み合わせごとの平均
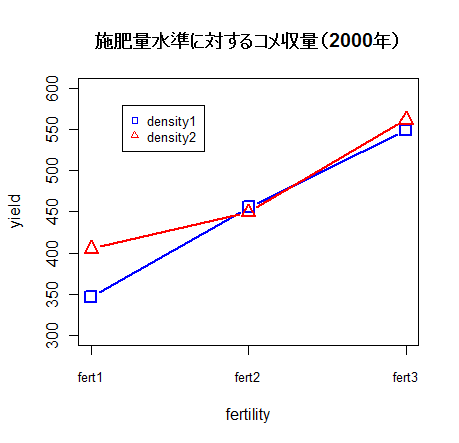
# 施肥量水準に対する収量のグラフ
plot(1:3, cm[1:3], type="b", lwd=2, cex=1.5, xaxt="n", xlab="fertility", ylab="yield",
ylim=c(300, 600), pch=0, cex.lab=1.0, cex.axis=1.0, col="blue")
axis(1, 1:3, labels=c("fert1","fert2","fert3"), cex.axis=0.8)
points(1:3, cm[4:6], type="b", lwd=2, cex=1.5, pch=2, col="red")
legend(1.2, 580, legend=c("density1","density2"), pch=c(0,2),
col=c("blue","red"), cex=0.8)
title(main="施肥量水準に対するコメ収量(2000年)")
# 分散分析
ry.aov <- aov(yield[1:12] ~ blk[1:12] + dense[1:12] + fert[1:12] + dense[1:12]:fert[1:12])
summary(ry.aov) #分散分析表の表示
|
注)blk[1:12] などは主効果であり,dens[1:12]:fert[1:12] は交互作用である.