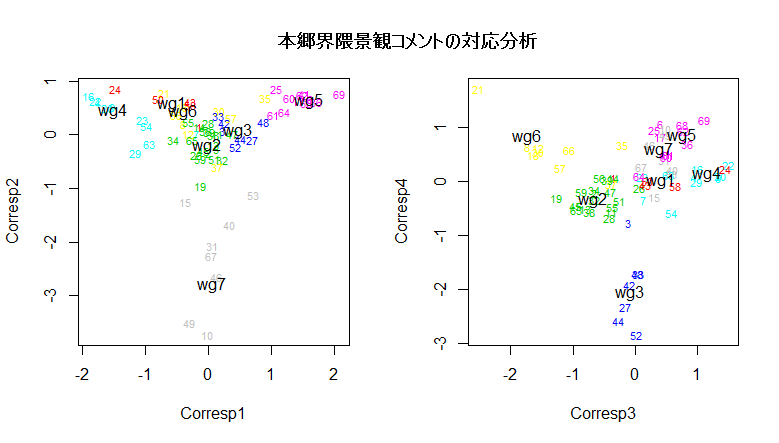
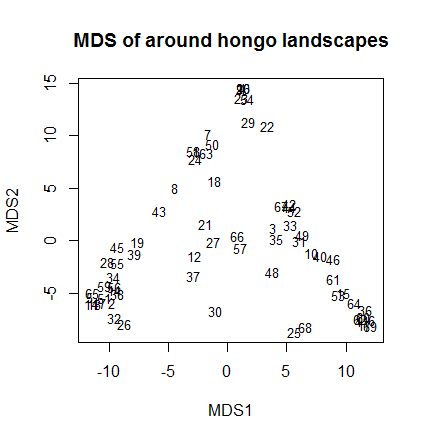
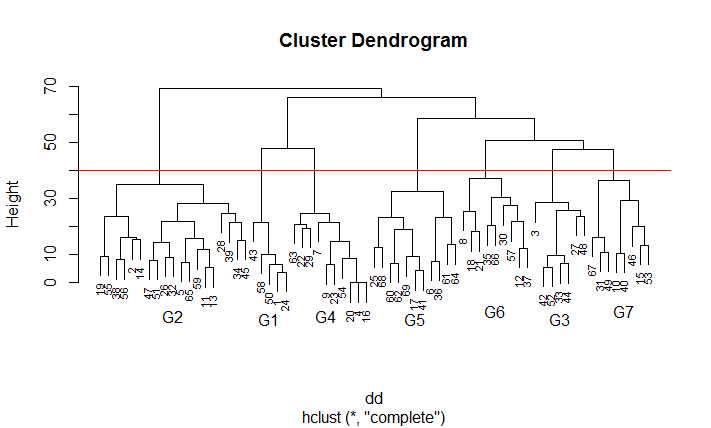
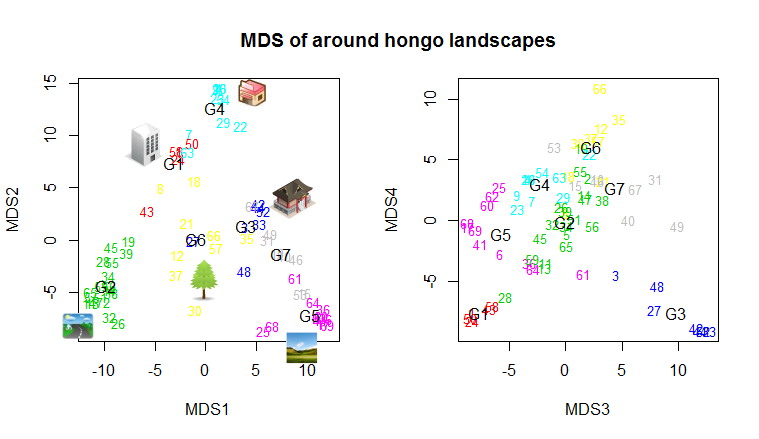
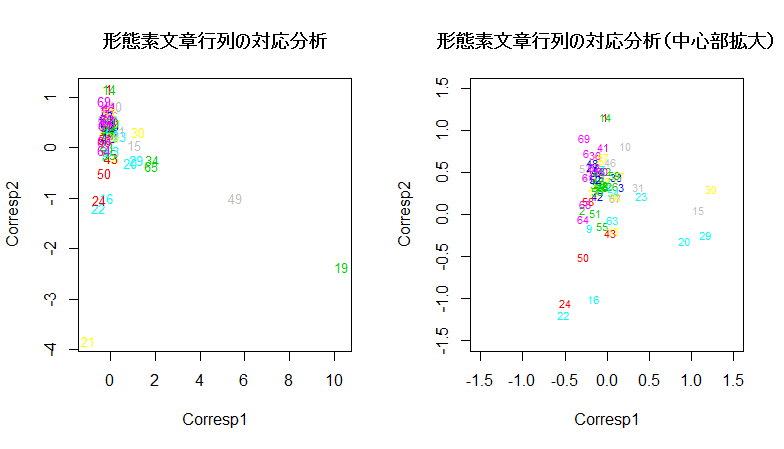
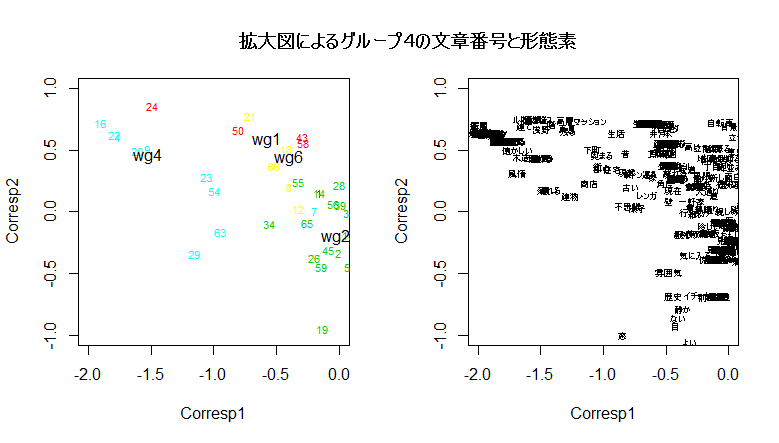
# 形態素文章行列の景観グループの対応分析の R スクリプト
wg1 <- apply(radj3[,g1],1,sum)
wg2 <- apply(radj3[,g2],1,sum)
wg3 <- apply(radj3[,g3],1,sum)
wg4 <- apply(radj3[,g4],1,sum)
wg5 <- apply(radj3[,g5],1,sum)
wg6 <- apply(radj3[,g6],1,sum)
wg7 <- apply(radj3[,g7],1,sum)
#
wonlyg1 <- which( (wg2+wg3+wg4+wg5+wg6+wg7)==0 )
wonlyg2 <- which( (wg1+wg3+wg4+wg5+wg6+wg7)==0 )
wonlyg3 <- which( (wg2+wg1+wg4+wg5+wg6+wg7)==0 )
wonlyg4 <- which( (wg2+wg3+wg1+wg5+wg6+wg7)==0 )
wonlyg5 <- which( (wg2+wg3+wg4+wg1+wg6+wg7)==0 )
wonlyg6 <- which( (wg2+wg3+wg4+wg5+wg1+wg7)==0 )
wonlyg7 <- which( (wg2+wg3+wg4+wg5+wg6+wg1)==0 )
#
radj4 <- cbind(radj3, wg1,wg2,wg3,wg4,wg5,wg6,wg7)
res4 <- corresp(radj4, nf=5)
colnames(res4$cscore) <- paste("Corresp", 1:5, sep="")
colnames(res4$rscore) <- paste("Corresp", 1:5, sep="")
biplot(res4, cex=0.5)
groupname <- paste("wg", 1:7, sep="")
op <- par(mfrow = c(1, 2))
com <- c(1,2)
plot(res4$cscore[,com], type="n")
text(res4$cscore[1:n,com], radname0, col=clclass+1, cex=0.7)
text(res4$cscore[(n+1):ncol(radj4), com], groupname)
com <- c(3,4)
plot(res4$cscore[,com], type="n")
text(res4$cscore[1:n,com], radname0, col=clclass+1, cex=0.7)
text(res4$cscore[(n+1):ncol(radj4), com], groupname)
par(op)
title(main="本郷界隈景観コメントの対応分析")